논문 제목 - Very Deep Convolutional Networks for Large-Scale Image Recognition
VGGNet은 2014년 ILSVRC에서 GoogleNet에 이어 2위를 차지한 Image Recognition Model이다.
Abstract
- Convolutinal network의 깊이가 정확도에 미치는 영향을 조사한 논문이다.
- 주요한 contribution : 매우 작은 3x3 콘볼루션 필터를 가진 아키텍쳐를 사용하여 깊이를 증가시키고 이를 평가
- 깊이를 16 - 19 층으로 설정
- ImageNet Challenge 2014에서 Localisation 분야 1위, Classification 분야 2위를 달성
1. Introduction
- 커다란 공공 이미지 저장소(이미지넷 같은)를 사용할 수 있게 되었으며 GPU나 large-scale distributed clusters 같은 높은 성능의 컴퓨터 시스템의 사용으로 인해 대규모 이미지 및 비디오 인식이 가능해졌다.
- 2012 AlexNet의 아키텍처를 개선하려는 많은 시도들이 있었다. (작은 receptive field, 작은 stride 등...)
- 본 논문에서는 아키텍처 설계의 중요한 측면인 깊이를 다룬다.
- 모든 계층에서 매우 작은 3x3 컨볼루션 필터를 사용하여 네트워크 깊이를 꾸준히 증가시킨다.
- VGGNet의 아키텍처는 ILSVRC의 classification 및 localisation task에서 SOTA일 뿐만 아니라 다른 이미지 인식 데이터 세트에도 적용할 수 있다.
2. ConvNet Configurations
- 공정한 환경에서 ConvNet 깊이 증가로 인한 개선을 측정하기 위해, 모든 ConvNet 계층 구성은 동일한 원칙을 사용하여 설계되었다.
2.1 Architecture


- Training 동안에, ConvNet의 input사이즈는 224x224로 고정된 RGB image이다.
- 유일한 전처리는 각각의 픽셀에 대해 훈련세트의 RGB 평균 값을 빼준 것이다.
- 매우 작은 receptive field인 3x3 필터를 사용하였다.
- 입력 채널의 선형 변환을 위해 1x1 필터를 사용하였다. 이는 비선형 함수를 거쳐 적용된다.
- stride는 1을 사용하였다.
- 공간 해상도 보존을 위해 3x3 필터에는 1 padding을 사용하였다.
- Max Pooling은 2x2크기에 stride는 2로 적용하였다.
- 컨볼루션 레이어들 뒤에는 3개의 Fully-Connected(FC) layer가 있다.
4096 -> 4096 / 4096 -> 4096 / 4096 -> 1000
- 마지막 레이어는 소프트맥스 층이다.
- 컨볼루션 레이어들의 구성은 모델마다 다르지만 FC레이어의 구성은 모두 동일하다.
- 모든 은닉층은 활성화 함수로 ReLU를 사용하였다.
- AlexNet에서 사용했던 LRN은 성능 향상을 가져오지 못하여 사용하지 않았다.
2.2 Configurations

- A ~ E 모델의 차이점은 오직 깊이이다.
- 첫번째 레이어에서 64채널로 시작해서 max pooling을 거칠 때 마다 채널을 2배로 늘려준다. 최종은 512에 도달한다.

- 깊이가 깊은데도 불구하고 더 큰 컨볼루션 레이어와 receptive field를 가진 얕은 모델보다 파라미터가 작다.
2.3 Discussion
- AlexNet에서 스트라이드 4인 11x11 필터를 사용하는 것과 달리 VGGNet에서는 전체에 3x3 필터를 사용한다.
- 2개의 3x3 필터를 쌓으면 5x5의 receptive field를 가진다.
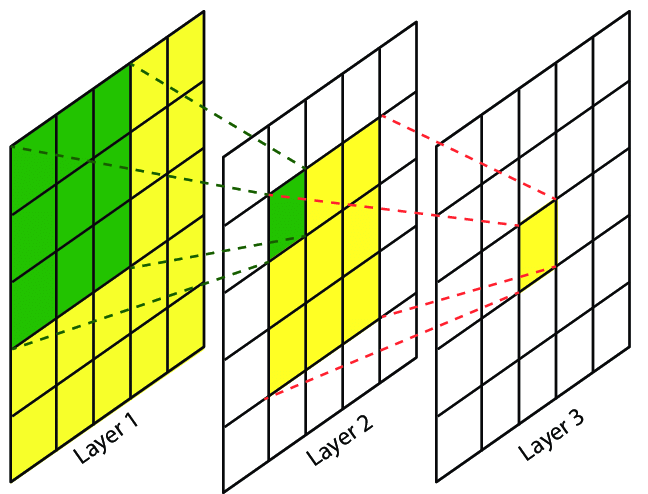
- 3개의 3x3 필터를 쌓으면 같은 원리로 7x7의 receptive field를 가진다.
- 하나의 7x7를 사용하는 대신 3개의 3x3 필터를 사용하면 이점이 무엇일까?
1. 활성화 함수를 1개 대신 3개 사용하여 비선형성에서 이점을 볼 수 있다.
2. 파라미터 수를 줄일 수 있다. 입력과 출력의 채널이 C라고 가정하면 3개의 3x3 필터의 파라미터는 $ 3(3^2C^2) = 27C^2 $ 1개의 7x7 필터의 파라미터는 $ 7^2C^2 = 49C^2 $ 로 3x3 필터를 이용한 경우가 파라미터가 적음을 볼 수 있다.
- 1x1 필터의 사용은 비선형성을 증가시키는 방법이다. 1x1 합성곱은 같은 차원을 유지시키지만 활성화 함수를 사용함으로써 비선형성을 증가시킨다.
3. Classification Framework
3.1 Training
- 이미지 crop 방식을 제외하고 AlexNet의 훈련 절차를 따른다.
- batch size = 256, momentum = 0.9, weight decay = $5*10^4$, learning rate = 0.01(validation set accuracy가 향상되지 않을 때마다 10배 감소시킴), iteration = 370,000(epoch = 74)
- AlexNet보다 많은 파라미터를 가지고 더 깊은데도 불구하고 수렴하는데 더 적은 epoch를 가진다. 이는 작은 필터사이즈를 사용한 것과 pre-initialisation을 사용했기 때문이다.
pre-initialisation
- 네트워크 가중치의 initialisation은 중요하다. 따라서 configuration A를 학습 시키고 나서 더 깊은 아키텍처를 학습시킬 때 처음 4개의 convolution layer와 마지막 3개의 FC layer를 net A의 layer를 이용하여 초기화한다.
- 고정된 224x224 크기의 ConvNet input image를 얻기 위해서 rescaled된 training images에서 무작위로 자른다. (아래에 자세히 설명)
- augmentation을 하기 위해 random horizontal flipping, random RGB colour shift를 사용하였고 rescaled된 훈련 이미지에서 랜덤하게 crop하였다.
Training image size.
(Training image rescaling 관련)
- image rescaling을 할 때 두가지 접근 방식을 취하였다.
1. 고정된 크기의 input size S
input size = 256 혹은 input size = 384로 고정하여 진행한다.
2. [256, 512] 범위에서 랜덤하게 rescaling (scale jittering)
물체가 다양한 사이즈로 나타나기 때문에 학습에 이점이 있다.
속도의 이유로 multi-scale 모델은 모든 층에 대해 사전학습된 input size=384의 모델을 fine-tuning하였다.

3.2 Testing
- 테스트 시에는 사전 정의된 가장 작은 Q 값으로 이미지 크기를 조절한다. Q는 학습 스케일 S와 일치하지 않을 수 있다.
- 그 다음 마지막 3개의 Fully-Connected layer를 Convolutional layer로 변환하여 사용한다.
첫 번째 FC layer는 7x7 Conv로, 마지막 두 FC layer는 1x1 Conv로 변환한다. 이렇게 변환된 신경망을 Fully-Convolutional Networks라 한다. (신경망이 Convolution layer로만 구성될 경우 입력 이미지의 크기 제약이 없어진다. 이에 따라 하나의 입력 이미지를 다양한 스케일로 사용한 결과들을 앙상블하여 이미지 분류 정확도를 개선하는 것도 가능해진다고 한다.)
- FC layer를 convolutional layer로 변환하여 전체 이미지에 적용한 결과는 클래스 수와 동일한 채널 수를 갖는 클래스 점수 맵이다. 이 점수 맵은 공간 해상도가 입력 이미지 크기에 따라 변한다. 최종적으로 이미지의 고정 크기 클래스 점수 벡터를 얻기 위해 클래스 점수 맵을 공간적으로 평균화한다. ?
- 이미지를 수평으로 뒤집어 테스트 세트를 증강한다. 원본 이미지와 뒤집은 이미지의 soft-max *posteriors를 평균하여 이미지의 최종 점수를 얻는다.
*posterior : 사후 확률
3.3 Implementation Details
- 구현은 C++ Caffe를 사용하였으며 4개의 GPU를 이용하였다. 이는 1개의 GPU를 사용할 때보다 3.75배 빨랐다.
- Multi GPU 학습은 데이터 병렬 처리를 이용하며, GPU 배치 기울기가 계산된 후 전체 배치 기울기를 얻기 위해 평균화된다.
[?] GPU 간 기울기 계산이 동기화되므로 단일 GPU에서 학습하는 것과 정확히 같은 결과가 나온다. -> Data parallelism... multi gpu training..
- 학습을 하는 데에는 2~3주가 소요되었다.
4. Classification Experiments
Dataset.
- dataset은 1000개의 클래스에 대한 이미지들이 포함되어 있으며 train(1.3M), validation(50K), test(100K)로 나누어 사용하였다.
- 분류 성능은 두 방법으로 측정되었다.
1. top-1 error : 잘못 분류된 이미지의 비율
2. top-5 error : top-5로 예측된 카테고리에 정답이 없는 이미지의 비율
- 실험은 validation set을 test로 사용하여 진행되었다.
4.1 Single Scale Evaluation

1. local response normalisation(LRN)은 사용하지 않았다. (모델 A로 비교 평가를 하였으나 성능 향상이 없었음)
2. ConvNet depth가 증가할수록 error가 감소하였다. (error rate : A > B > C > D > E)
3. train때 scale jittering을 하였더니 상당히 결과가 좋게 나왔다.
4.2 Multi-Scale Evaluation

- test time에서 scale jittering을 적용한 것이 더 나은 성능을 보인다.
- 깊은 모델의 성능이 더 좋았다.
- train time에서 scale jittering을 적용한 것이 smallest side S를 고정한 것 보다 좋은 성능을 보였다.
4.3 Multi-Crop Evaluation

- multi-crop, dense 기법을 적용한 결과이다. 둘 다 적용한 것이 성능이 제일 좋았다.
4.4 ConvNet Fusion

- ILSVRC 제출에 7개의 모델을 앙상블 한 네트워크를 제출하였다. (에러율 : 7.3%)
- 제출 이후 2개의 성능이 가장 좋은 multi-scale model(D, E)를 앙상블하여 성능이 향상되었다. (에러율 : 7.0%)
4.5 Comparison with the state of the art

- ILSVRC에서 2위를 달성했다. (1위 GoogLeNet)
5. Conclusion
- 표현 깊이는 분류 정확도에 유리하다!
'논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] ResNet(2016) (0) | 2023.03.09 |
|---|
