네이버 부스트코스의 '컴퓨터 비전의 모든 것' 정리 내용입니다.
2. 컴퓨터 비전과 딥러닝
데이터 부족 문제 완화
Data Augmentation
Neural network는 데이터에 포함된 정보를 압축하여 weight로 주입하는 모델
즉 모델이 데이터를 기반으로 학습되기 때문에 데이터의 퀄리티에 따라 성능이 좌우
허나 현실의 데이터는 모두 bias가 존재. 가령 인터넷 상에 존재하는 수많은 이미지 데이터를 활용한다고 했을 때, 사람이 촬영한 이미지는 대부분 사람이 보기 좋은 구도로 촬영되었기 때문에 bias가 데이터에 존재한다고 볼 수 있을 것
또한 이 세상의 모든 데이터를 확보하는 것은 불가능하기 때문에, 실제로 사용하게 되는 데이터는 real data distribution에서 샘플링된 일부라고 볼 수 있다.
그렇다면 데이터에 bias가 존재하는 것이 왜 문제가 될까?

가령 밝은 이미지로만 구성된 학습 데이터셋을 가정할 때, test time에서 한번도 보지 못했던 어두운 고양이 사진이 입력된 경우에 올바른 분류를 수행하기 어려울 것
이는 데이터셋이 충분히 real data distribution을 표현하지 못했기 때문에 발생한 문제
그렇다면 어떻게 real data distribution과의 차이를 좁힐 수 있을까?
물론 보다 많은 양의 편향되지 않은 데이터를 확보하면 되겠지만, 빠르게 모델을 개발해야하는 현실 상황에서 언제까지나 데이터 확보에만 시간을 쏟을 순 없을 것
Real data distribution과의 차이를 완화할 수 있으면서도 현실적으로 활용할 수 있는 방안 중 하나가 바로 Data Augmentation. 학습 데이터의 이미지를 기반으로 이미지 회전, 밝기 조절 등과 같은 기본적인 동작을 수행하여 학습 데이터의 사이즈를 증가시키는 방법
Image Data Augmentation에서는 주로 기본적인 이미지 처리 기법을 활용한다. 이미지 크롭(crop), 기하학적/색상/밝기 변경, 회전 등이 있으며 OpenCV 등의 라이브러리에 사용하기 쉽게 구현되어 있다.
Annotation Efficient Learning
Transfer Learning
Transfer Learning : 한 데이터셋에서 학습하며 배웠던 지식을 다른 데이터셋에서 활용하는 기술
이를 활용하면 기존에 미리 학습한 지식을 통해서 연관된 새로운 task에 적은 양의 학습 데이터로도 비교적 높은 성능을 달성할 수 있기 때문에 매우 경제적이면서도 강력한 방법
그렇다면 Transfer Learning이 잘 동작하는 이유는 무엇일까?

위의 그림은 서로 다른 4개의 task를 위한 데이터셋. 즉 다른 특성을 가진 데이터셋이라고 볼 수 있다.
허나 모두 이미지 데이터셋이라는 공통점이 있으며, 심지어 일부 공통된 패턴을 확인할 수 있다. 가령 (a) 데이터셋의 승용차 이미지에서 차량 바퀴와 (b) 데이터셋의 트럭 이미지에서 차량 바퀴를 공통된 패턴으로 확인할 수 있다. 이렇게 한 데이터셋을 통해 학습한 지식이 다른 데이터셋에서도 공통된 부분이 많아 유의미하게 활용될 수 있지 않을까? 라는 것으로 부터 Transfer Learning이 고안되었다.

Transfer Learning에도 여러가지 방식이 있다. 첫 번째 방식은 사전 학습된 모델에서 마지막 FC layer들만 떼어내고, 새로운 FC layer들로 교체하여 기존 모델 가중치들은 학습시키지 않고(freeze), 새로 교체한 FC layer의 가중치만 업데이트하는 방식
적은 파라미터만 학습시키면 되기 때문에 작은 사이즈의 데이터셋으로도 비교적 좋은 성능을 기대할 수 있다.

두 번째로는 전체 모델을 그대로 fine-tuning하는 방식. 새로운 FC layer들로 교체하는 것은 동일하지만 Convolution layer의 가중치 또한 업데이트를 진행. 다만 사전 학습된 지식을 최대한 보존하기 위해 Convolution layer의 learning rate는 FC layer에 비해 작은 값으로 설정하여 학습을 진행. 첫 번째 방식의 경우 데이터의 사이즈가 정말 작은 경우 활용하기 좋은 방법이라고 볼 수 있고, 그보다는 좀 더 데이터의 사이즈가 크다면 두 번째 방식을 활용하는 것이 적합
Knowledge Distillation

Knowledge Distillation도 매우 간단하면서 강력한 방법
사전에 학습한 Teacher model을 활용하여 그보다 작은 Student model을 학습시키는 방법
큰 모델의 지식을 작은 모델에 효과적으로 주입하는 방식으로 모델 압축에 주로 활용되는 방법
또한 레이블링되지 않은(unlabeled) 데이터셋에 pseudo-lableling을 적용하기 위한 목적으로도 활용

먼저 사전 학습시킨 Teacher model을 준비하고, Student model을 초기화
이후 같은 입력 X에 대한 Teacher model과 Student model의 각 출력을 바탕으로 KL divergence loss를 계산하여 Student model을 학습. 이때 KL divergence loss를 활용할 경우 두 출력 간의 distribution이 비슷하게 만들어지도록 학습이 진행되기 때문에, Student model이 Teacher model의 행동을 모방하도록 학습시키는 방식
레이블링된 데이터가 한정적인 상황에서, 레이블링되지 않은 데이터를 활용하여 성능을 높히는 방법
Semi-supervised Learning
Semi-supervised Learning은 레이블링된 데이터를 활용하는 것과 더불어 레이블링되지 않은 데이터를 효과적으로 학습에 활용하는 학습 방법
즉 두 가지 데이터를 모두 학습에 활용하여 데이터 부족 문제를 효과적으로 완화하는 방법
다음의 그림과 같이 pseudo-labeling을 활용하는 방법이 있다.
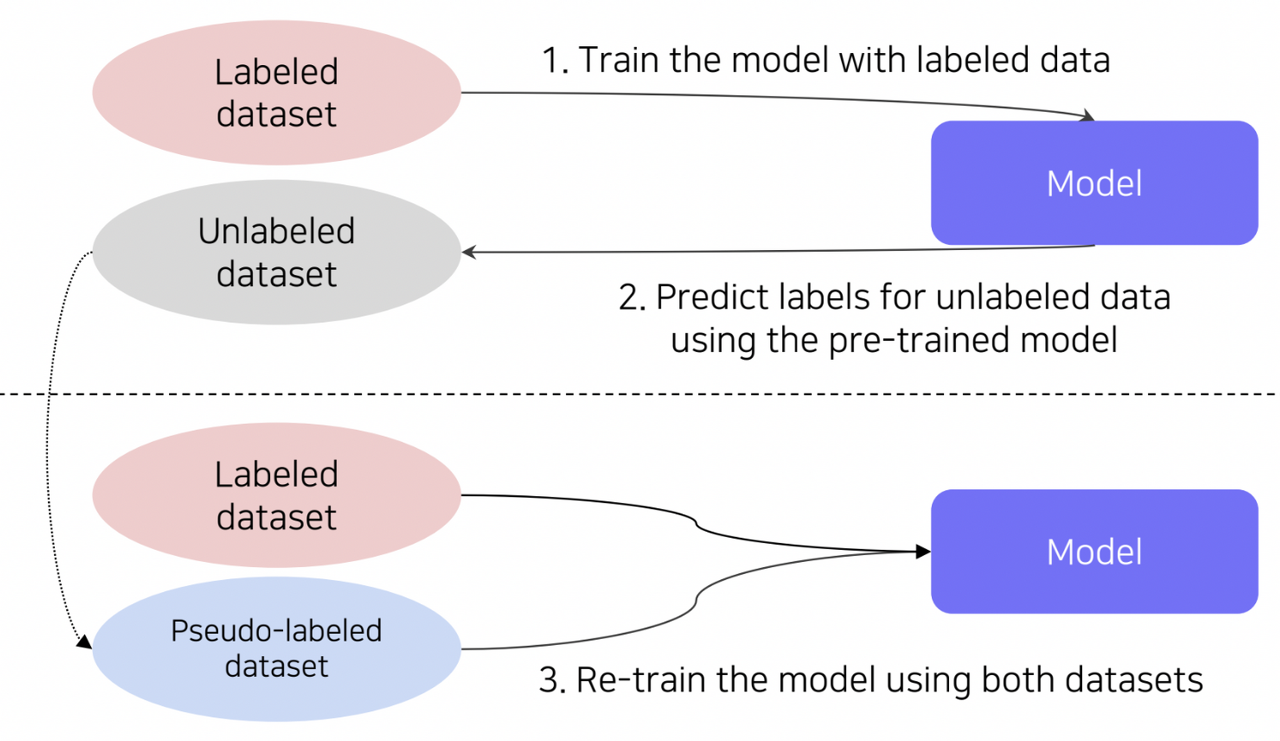
먼저 레이블링된 데이터를 활용하여 모델을 학습. 이후 레이블링되지 않은 데이터에 대해 학습된 모델을 활용하여 레이블을 예측(pseudo-labeling). 이후 pseudo-labeled 데이터셋과 레이블링된 데이터를 합하여 보다 큰 사이즈의 데이터셋으로 새롭게 모델을 학습
Self-training
지금까지 컴퓨터 비전 분야에서 데이터 부족 문제를 해결하기 위한 방법으로 Data Augmentation, Knowledge Distillation, Semi-supervised Learning을 살펴보았다.
이 방법들을 잘 결합하면, 2019년 ImageNet classification에서 SOTA 성능을 달성했던 Self-training 방법으로 활용할 수 있다.
생각해보기
- 본 강의에서 설명하였듯이 High-quality labeled dataset을 구축하는 일은 매우 어렵습니다. 그렇다면 dataset의 품질은 어떻게 평가하고 검증할 수 있을까요?
- 본 강의에서 소개되진 않았지만, unlabeled dataset을 효과적으로 사용하기 위한 방법으로 Self-supervised Learning도 굉장히 활발하게 활용되고 있습니다. 본 강의에서 학습한 내용을 기반으로 Self-supervised Learning의 개념을 스스로 학습해봅시다.
'머신러닝, 딥러닝 > 컴퓨터비전' 카테고리의 다른 글
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (3. Seg & Det - 1) (0) | 2023.02.05 |
|---|---|
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (2. 컴퓨터 비전과 딥러닝 - 2) (0) | 2023.02.05 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (1. 컴퓨터 비전의 시작) (0) | 2023.02.04 |
| 컴퓨터비전 용어 정리 (0) | 2023.01.17 |
| DeepFaceLab 사용 방법 (Window) (2) | 2023.01.16 |


