네이버 부스트코스의 '컴퓨터 비전의 모든 것' 정리 내용입니다.
Semantic Segmentation
What is Semantic Segmentation?

앞서 살펴보았던 Image Classification이 이미지 단위로 분류를 수행하는 거라면, Semantic Segmentation은 픽셀 단위로 분류를 수행하는 것이라 볼 수 있다. 하나의 픽셀이 사람에 속하는지, 오토바이에 속하는지, 자동차에 속하는지 등을 분류하는 task
이때 주의할 점은 여러 명의 사람을 각각 사람1, 사람2, ... 이런 식으로 한명한명 구분하는 것이 아니라 모두 "사람"으로 분류한다는 점이다.
Where can Semantic Segmentation be applied to?
그렇다면 Semantic Segmentation은 어떤 분야에 활용될 수 있을까?
위의 사진에서 확인할 수 있듯이 의료 이미지나 자율주행자동차 등 영상 내의 장면을 이해하는 부분에 활용
Semantic Segmentation Architectures
Fully Convolutional Networks (FCN)
FCN은 Semantic Segmentation을 위해 제안된 첫 번째 end-to-end 모델
이전에는 다양한 알고리즘을 결합하여 사용했기 때문에 학습가능한 부분이 적었던 반면, FCN의 경우 입력 단부터 출력 단까지 모두 학습가능한 end-to-end 구조를 가진다.
또한 입력 이미지의 해상도와 상관없이 동작할 수 있어 호환성이 높은 구조를 가진다고 볼 수 있다.
그럼 FCN의 구조를 구체적으로 살펴보겠다.
먼저 Fully connected layer에 대해서 리마인드를 하자면, 이는 이전 convolutional layer에서 출력된 feature map을 flattening하여 입력으로 사용했었다. 즉 이미지의 공간 정보를 고려하지 않는 것
그럼 이를 어떻게 바꿔야 각 픽셀 위치마다 classification을 수행할 수 있도록 만들어 줄 수 있을까?
각 픽셀 위치마다 채널 축으로 flattening하여 각 위치에 해당하는 벡터를 각각 구하면 된다.
1x1 convolution이 이러한 연산을 수행
각 필터들이 하나의 weight column과 같이 동작하여, 공간 정보를 고려할 수 있고, 채널 수 만큼의 feature map을 얻을 수 있는 것
따라서 FCN에서도 fully connected layer 대신 1x1 convolution을 사용하였으며, 이를 통해 어떤 입력 사이즈에도 대응가능한 Fully convolutional network를 가질 수 있는 것
허나 이러한 구조를 가져가더라도 넓은 receptive field를 확보하기 위해 pooling을 진행할 수록 저해상도의 출력을 얻게되는 문제가 발생
FCN에서는 이를 극복하기 위해 위의 그림과 같이 upsampling layer를 사용
이러한 구조를 가져감으로써 넓은 receptive field를 통해 입력의 context를 잘 고려하면서도 출력의 저해상도 문제를 해결할 수 있는 것
Upsampling 방법으로는 주로 Transposed convolution, Upsample and convolution 사용하기 때문에, 이들을 간략히 소개하도록 하겠다.
Transposed convolution을 보다 쉽게 이해하기 위해 1D로 펼쳐둔 그림은 위와 같다.
먼저 입력과 필터를 곱하여 각각 해당하는 위치에 출력하는 방식이며, 겹치는 위치의 경우 그 값을 합하여 출력
그렇기 때문에 중첩되는 부분에서 checkerboard artifact가 관찰되는 이슈가 있기도하다.
따라서 Transposed convolution을 활용할 때, 이러한 이슈를 주의하여 stride와 filter 사이즈를 설정해주어야 한다.
이러한 어려움을 극복하면서도 쉽게 활용할 수 있는 방법이 바로 Upsample and convolution이다.
말그대로 전체 upsampling 과정을 두 단계로 분리하여, 먼저 Nearest-neighbor, Bilinear interpolation 등의 interpolation 과정을 통해 upsample시키고, 다음으로 학습가능한 형태를 더해주기 위해 이를 convolution layer를 통과시키는 방법
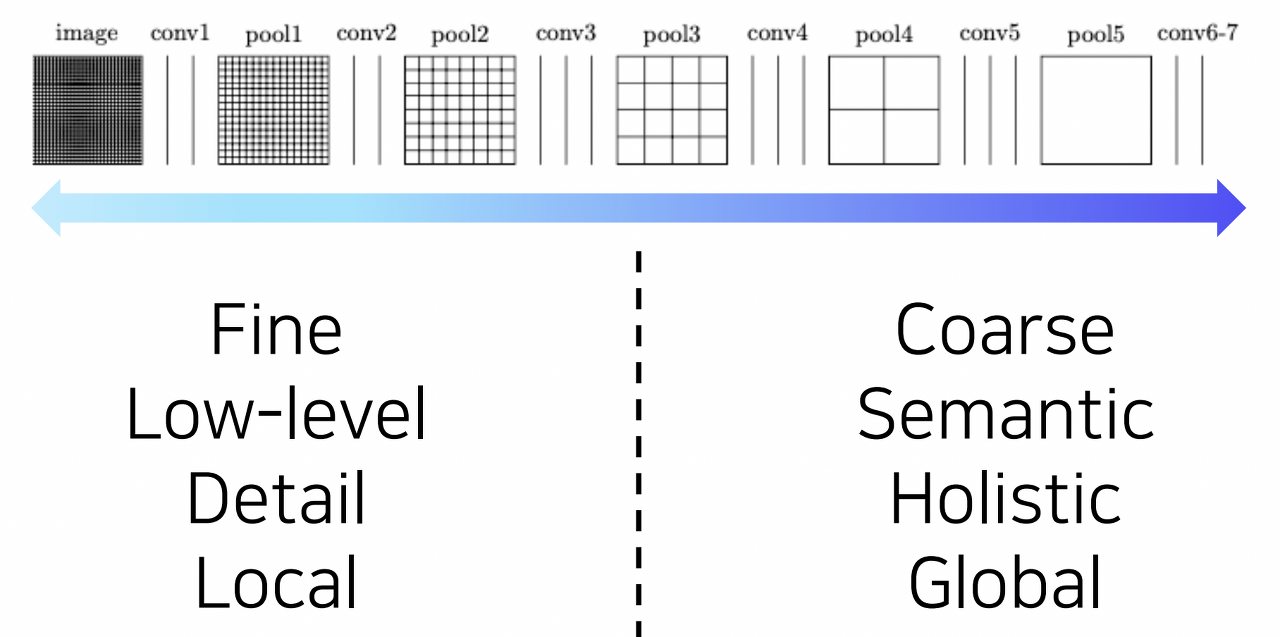
다시 FCN으로 돌아와 그 특징을 살펴보겠다.
FCN의 각 레이어 별로 feature map의 해상도와 의미를 살펴보면 위의 그림과 같다.
낮은 레이어의 경우 디테일한 부분들에 대한 특징, fine-grained한 특징에 대한 정보를 가지고 있고, 높은 레이어의 경우 보다 coarse한 레벨, 전반적이고 의미론적인 특징에 대한 정보를 담고 있다.
허나 semantic segmentation을 위해서는 이 두 가지 정보가 모두 필요하다.
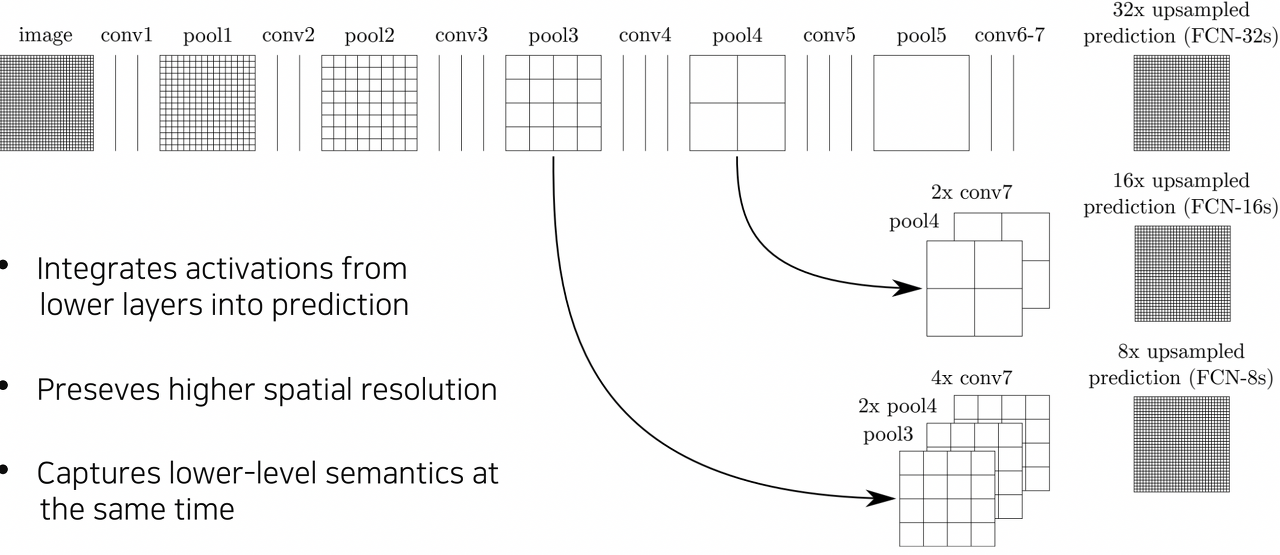
따라서 FCN에서는 skip connection을 사용하여 낮은 레이어의 feature map을 직접적으로 고려할 수 있도록 설계
이에 따라 보다 디테일한, 지역적인 특징을 잘 고려할 수 있는 것
이때 ResNet의 skip connection처럼 단순히 합해주는 것이 아닌 concatenation을 수행하준다는 차이점이 있다.
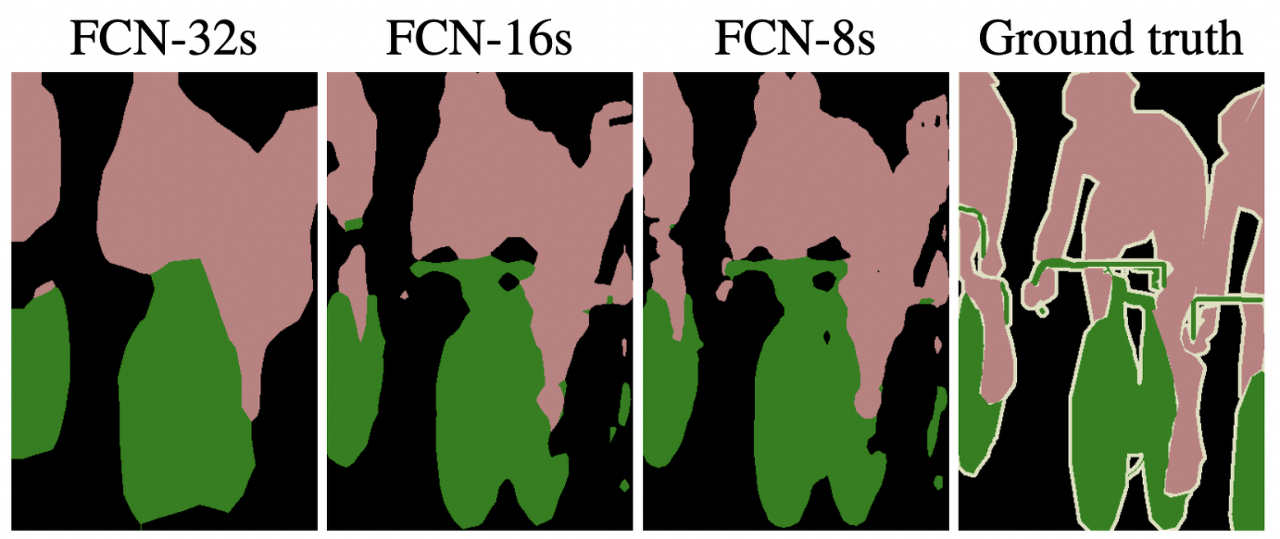
결과를 살펴보면 위의 그림과 같은데, 실제로도 중간 레이어의 feature map을 잘 고려하고 있는 경우에 더 좋은 semantic segmentation 결과를 보여주는 것을 확인할 수 있다.
Hypercolumns for Object Segmentation
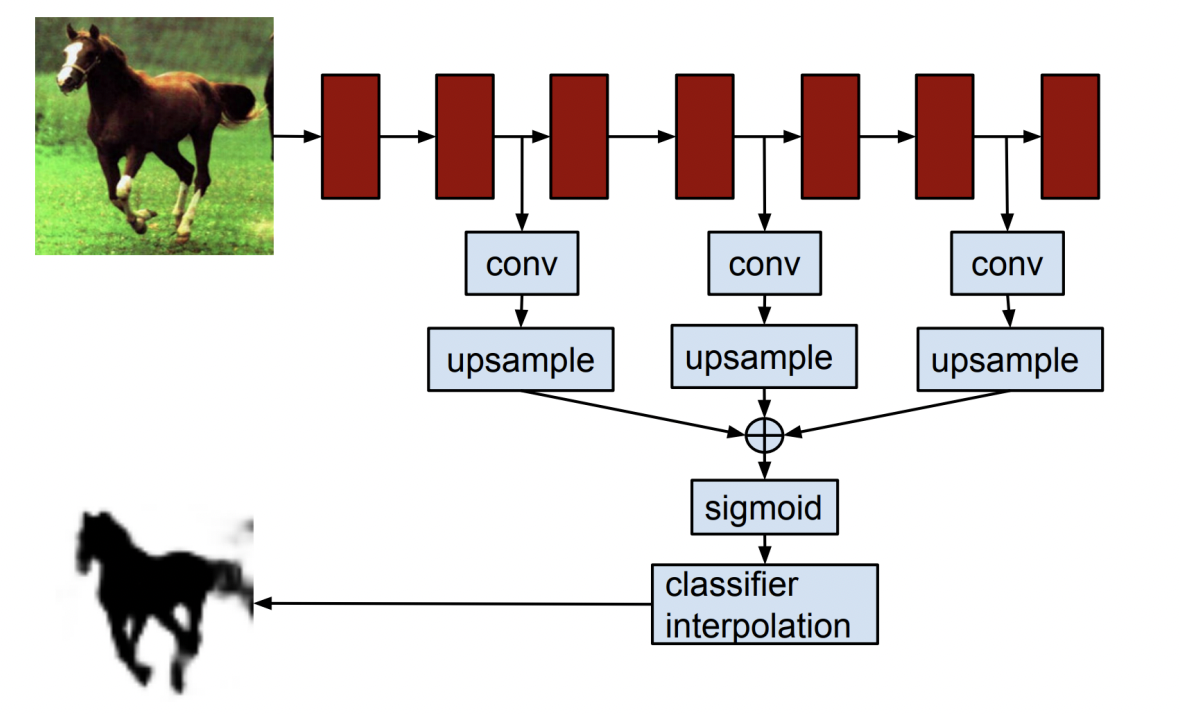
Hypercolumn이라는 모델 또한 FCN과 굉장히 유사한 아이디어를 기반으로 제안된 모델이다. 허나 Hypercolumn에서는 낮은 레이어의 특징과 높은 레이어의 특징의 결합을 가장 강조하고 있다는 점에서 FCN과 차이가 있다. 그 구조는 위의 그림과 같은데, 여기서도 별도의 알고리즘을 사용하여 얻은 물체의 bounding box를 입력으로 사용한다는 점에서 FCN과 차이가 있다.
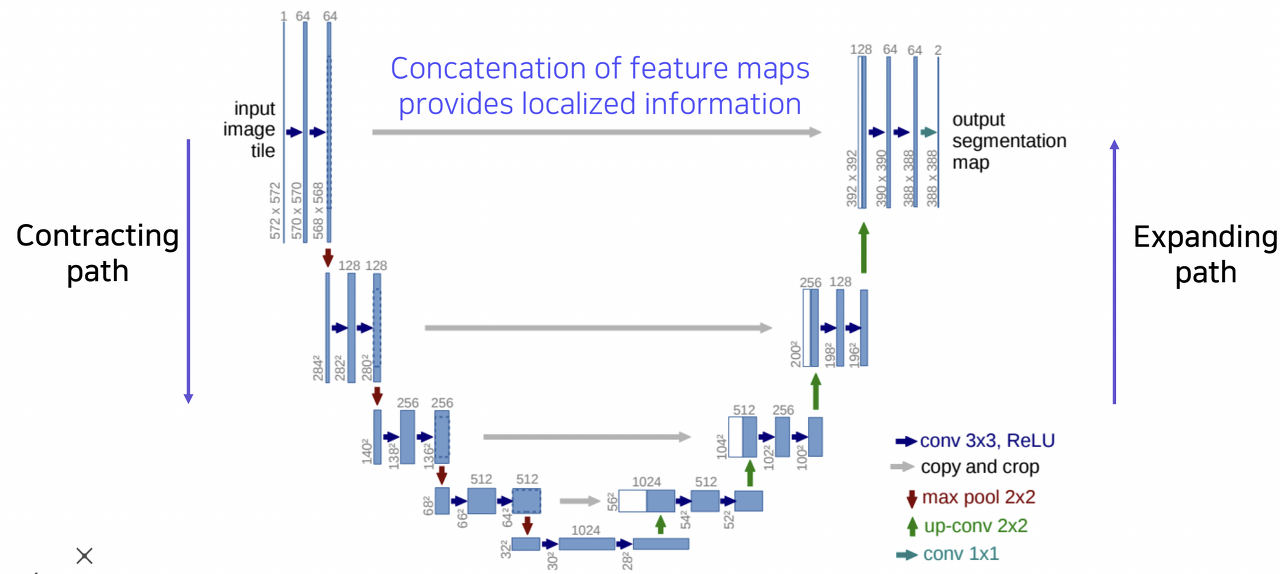
다음은 Semantic Segmenation 뿐만 아니라 다양한 Computer Vision task에서 강력한 성능을 보여줬던 U-Net이다. 위의 그림과 같이 U-Net은 대칭적인 downsampling, upsampling 과정(contracting path, expanding path)을 거치는 구조를 가지고 있다. Downsampling 과정에서는 pooling을 통해 공간해상도를 절반으로 줄이고, 채널 수를 두배로 늘리는 방식으로 feature map을 얻고 있으며, upsampling 과정에서는 반대로 공간해상도를 두배로 늘리고, 채널 수는 절반으로 줄이는 방식으로 segmentation map을 얻고 있다. 그리고 각 과정에서 대칭적으로 대응하는 부분을 보면, skip connection을 통해 지역적인 정보를 담고있는 downsampling 과정에서의 feature map을 upsampling 과정의 segmentation map에 concatenation 해주고 있는 것을 확인할 수 있다.
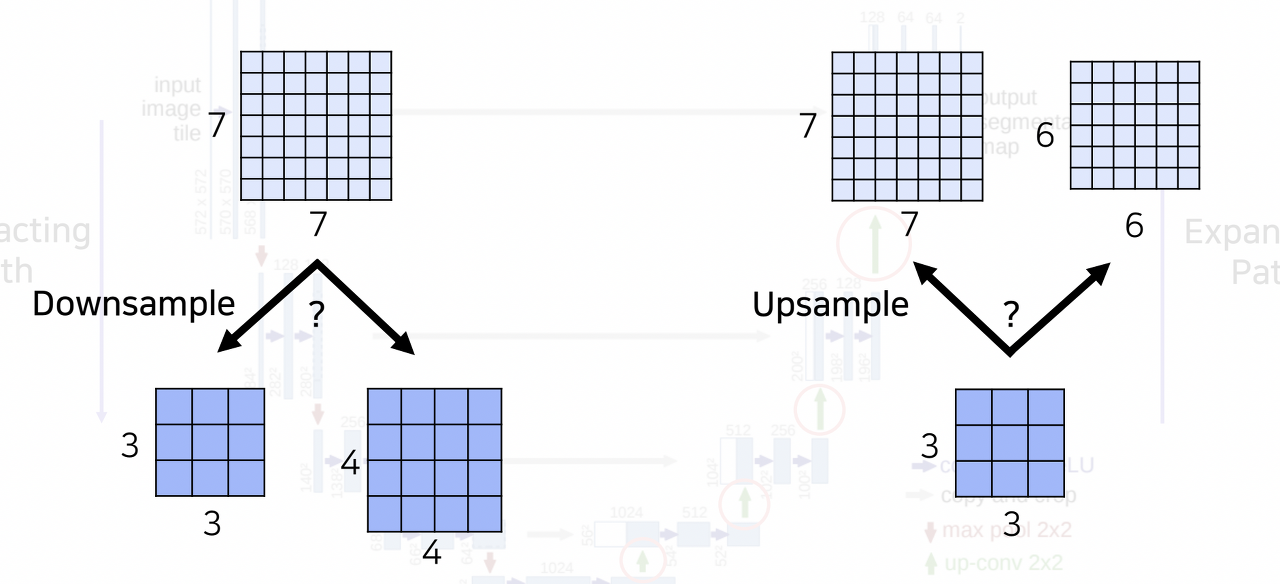
그럼 혹시 홀수의 공간해상도를 가지는 feature map이 입력된다면 어떻게 처리할까? 그림과 같은 예시를 살펴보겠다. 7x7 입력이 주어졌을 때 downsampling 과정에서 3x3 혹은 4x4를 출력해야한다. 허나 대칭되는 upsampling 과정에서 3x3 혹은 4x4의 입력이 들어온다면, 7x7 출력으로 복구될 수 있을까? 아니다. 6x6 혹은 8x8이 출력될 것이다. 허나 Contracting path에서의 feature map을 expanding path에서 대응되는 부분에 concatenation 시켜주기 위해서는 공간해상도가 맞아야 한다. U-Net에서는 이러한 문제를 어떻게 구현하여 해결하고 있는지 PyTorch 코드와 함께 살펴보도록 하겠다.
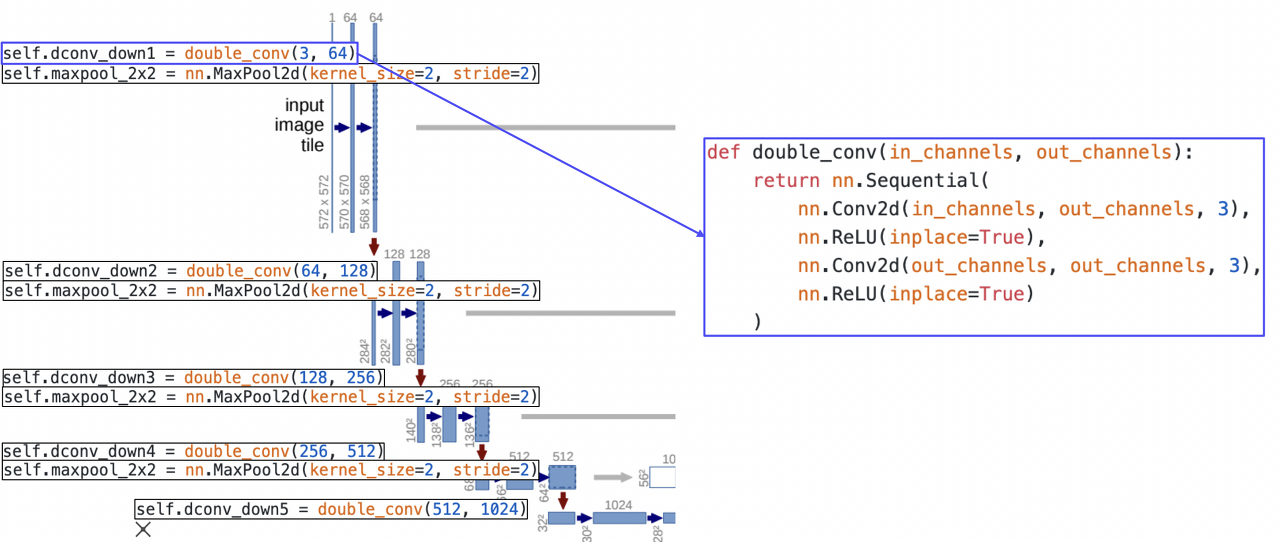
먼저 위의 코드는 downsampling 과정을 구현한 코드이고, 우측은 편의를 위해 구현한 double_conv 함수이다. double_conv 함수는 말그대로 두 번 convoution(+ ReLU)을 수행해주는 block이다. 또한 각 contracting path에서는 이 double_conv를 수행하고, 이어서 max pooling을 수행하는 과정을 거친다.
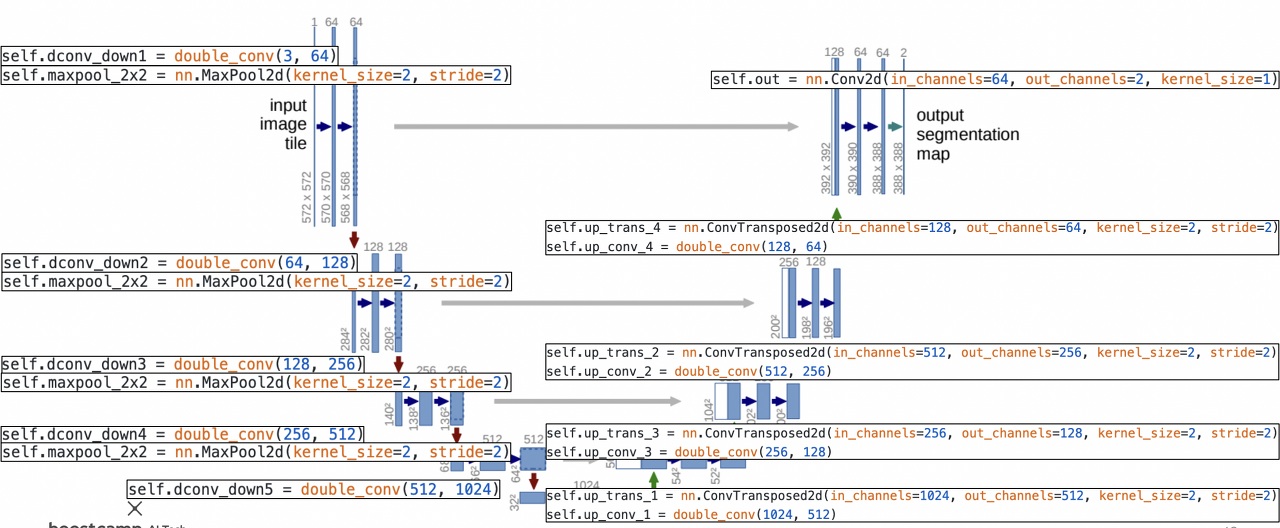
위와 같이 Upsampling 코드까지 더하여 살펴보겠다. 각 Expanding path에서는 upsampling을 위한 transposed convolution이 사용된다. 이때 매개변수를 살펴보면 kernel size와 stride가 모두 2인 것을 확인할 수 있는데, 이에 따라 transponsed convolution을 수행하게 되면 이전에 이야기했던 checkerboard artifact 이슈를 발생하지 않는다. 전체적인 코드는 앞서 설명한 것과 마찬가지로 해상도는 두 배로 늘리고, 채널 수는 절반으로 줄이는 과정을 반복하는 동작을 구현한 코드이다.
DeepLab

마지막으로 Semantic Segmantation에서 중요한 한 획을 그었던 DeepLab을 알아보도록 하겠다. 관련하여 세 가지의 주요 개념을 살펴보겠다.

첫 번째로 후처리 도구로 활용되는 Conditional Ramdon Fields(CRF) 이다. Neural network를 기반으로 semantic segmentation을 수행했을 때 위 그림과 같이 경계가 흐릿한 결과를 확인할 수 있다. 이는 neural network이 출력을 입력과 비교하는 feedback loop이 부재한 단순 feed forward 구조를 가지고 있기 때문이고, 이를 극복하기 위해 rough한 score map과 이미지의 edge를 추출한 경계선을 활용하여 해당 score map이 경계선이 잘 맞아떨어지도록 반복적으로 확산을 시켜준다. 실제로 그 결과를 확인해보면, 10번의 iteration을 수행한 경우 최우측 이미지와 같이 경계에 잘 들어맞는 segmentation map을 출력하는 것을 확인할 수 있다.
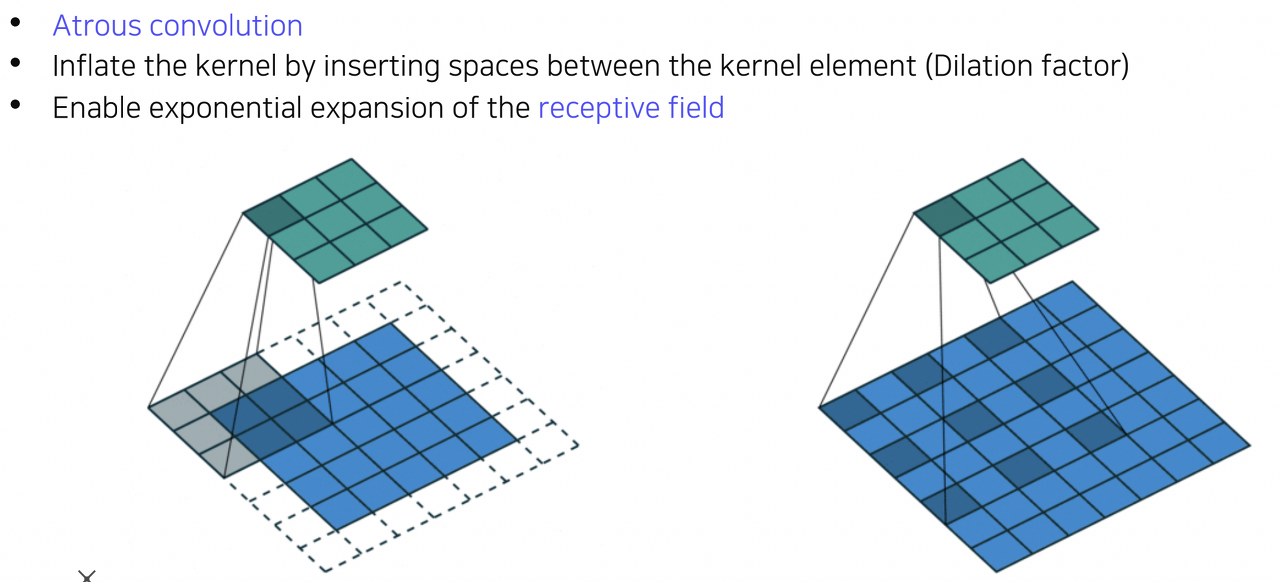
두 번째로 Dilated convolution 이다. 이는 convolution filter들 사이에 dilation factor 만큼 space를 넣어주는 방법이다. 이를 통해 실제 convolution filter보다 넓은 영역을 고려할 수 있는, 즉 지수적으로 receptive field를 확장할 수 있는 방법이다.
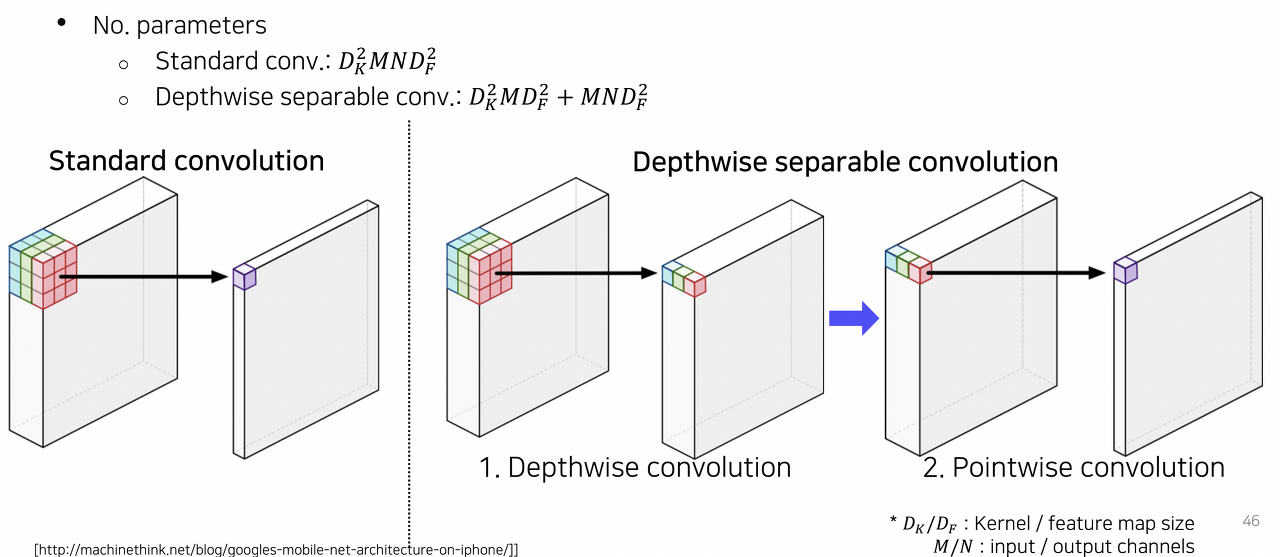
세 번째로 Depthwise separable convolution 이다. DeepLab v3+에서는 semantic segmentation의 입력 해상도가 워낙 크기 때문에 연산이 복잡해지는 것을 완화하기 위해 dilated convolution을 depthwise separable convolution과 결합하여 사용한다. Standard convolution의 경우 하나의 출력 픽셀에 대한 activation을 얻기 위해 전체 필터 사이즈의 크기를 채널 축으로 내적하는 과정을 거친다. 이에 필요한 연산을 따져보면 $D_k^2MND_F^2$이다. 반면 Depth-wise convolution은 이 절차를 두 개의 과정으로 나눈다. 먼저 각 채널 축으로 convolution을 수행하여 각 채널에 대한 값을 추출하고, 이를 point-wise convoltuion, 즉 1x1 convolution을 통해 하나의 activation으로 추출한다. 이러한 방식을 사용하게 되면, convolution의 표현력도 유지할 수 있으면서, 필요한 연산은 $D_K^2Md_F^2 + MND_F^2$로 standard convolution에 비해 연산량을 크게 줄일 수 있게 된다.
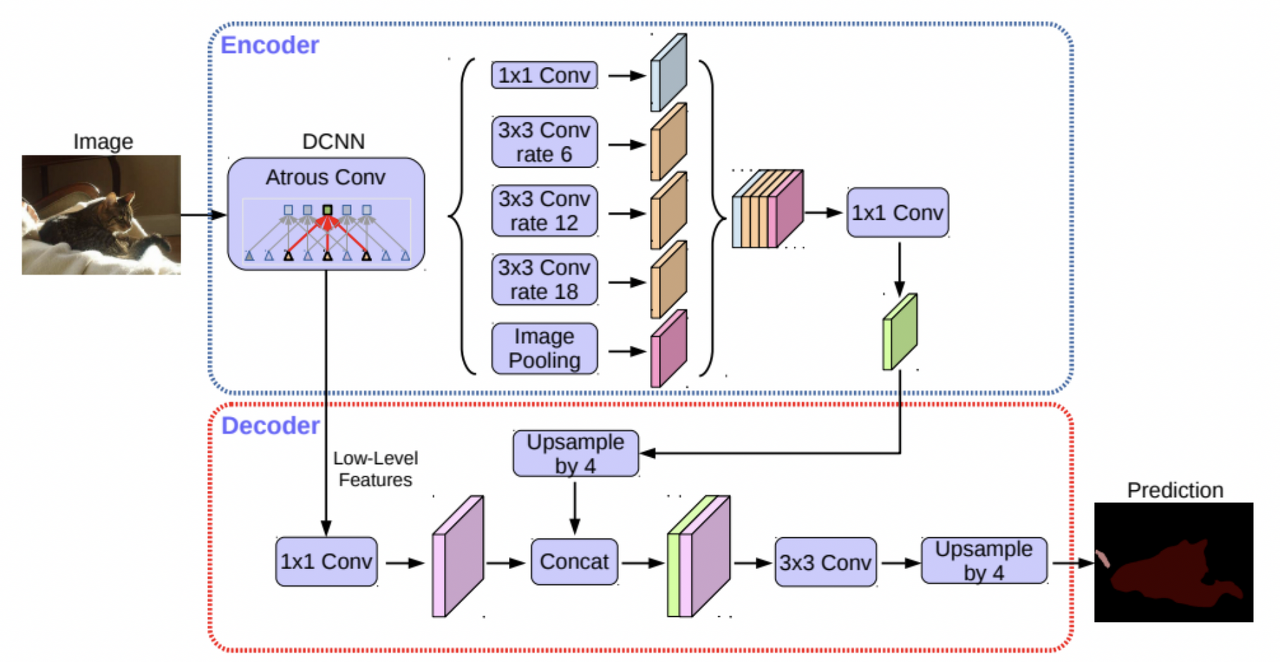
마지막으로 DeepLab v3+의 구조를 살펴보면 위의 그림과 같다. 먼저 dilated convolution을 적용하며, 일반적인 convoltuion 보다 큰 receptive field를 가지는 convoltution을 수행해준다. 또한 영역 별로 주변 물체와의 거리, 연관된 정보들이 서로 다르기 때문에 multi-scale을 다룰 수 있도록 spatial pyramid pooling을 수행해준다. 이렇게 얻은 feature map들을 concatenation한 이후에 1x1 convolution을 적용하여 하나로 합쳐준다. 그 이후에는 Decoder 단에서 낮은 레이어의 feature map과 pyramid pooling을 거친 feature map을 concatenation 시켜준다. 이를 upsampling하여 최종적인 segmenation map을 출력하는 구조이다.
생각해보기
- 본 강의에서는 Semantic Segmenation은 가장 기본적인 모델과 FCN을 기반으로 skip connection 방법을 개선한 U-Net, receptive field를 확장시킨 DeepLab을 살펴보았습니다. 이외에도 다양한 방법으로 FCN을 개선한 모델이 많은데, FCN을 어떻게 개선할 수 있을지 스스로 생각해봅시다.
'머신러닝, 딥러닝 > 컴퓨터비전' 카테고리의 다른 글
| COCO, Pascal VOC data format (Object detection) (0) | 2023.04.21 |
|---|---|
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (3. Seg & Det - 2) (0) | 2023.02.13 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (2. 컴퓨터 비전과 딥러닝 - 2) (0) | 2023.02.05 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (2. 컴퓨터 비전과 딥러닝 - 1) (0) | 2023.02.05 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (1. 컴퓨터 비전의 시작) (0) | 2023.02.04 |



