네이버 부스트코스의 '컴퓨터 비전의 모든 것' 정리 내용입니다.
2. 컴퓨터 비전과 딥러닝
영상 인식의 이해
Image Classificaiton (2) : 대표 모델
Problems with Deeper Layers
Going Deeper with Convolutions
AlexNet과 VGGNet이 등장하면서 연구자들은 네트워크가 깊을수록 receptive field가 커지고, 더욱 복잡한 관계에 대해 학습이 가능하다는 강력한 특징들을 가진다는 것을 확인하였다. 그렇기 때문에 네트워크를 더욱 더 깊게 쌓으려는 움직임이 이뤄졌는데, 과연 네트워크를 단순히 깊게 쌓는다고 해서 무조건 성능이 향상될까?
Hard to Optimize
단순히 네트워크를 깊게 쌓게된다면 최적화하기 어렵다는 문제가 발생한다. 대표적인 원인으로 Gradient Vanishing/Exploding 현상이 있는데, 이는 깊은 네트워크에서 역전파 알고리즘을 수행할 경우, Gradient 값이 너무 커지거나(Exploding), 소실에 가까울 정도로 너무 작아지는(Vanishing) 현상이다. 추가적으로 계산복잡도가 증가하여 하드웨어 요구사항이 까다로워지는 등의 원인이 있다.

GoogLeNet에서는 Inception module이라는 새로운 구조를 제안했다. 이는 하나의 층에서 다양한 사이즈의 필터를 활용하고,이후 각 필터를 거친 출력 값을 channel 축으로 concat해줌으로써, 다양한 측면의 특징을 추출하겠다는 시도로 볼 수 있다.
허나 한 층에서 많은 수의 필터를 활용하게 되면 당연히 파라미터의 수가 증가하고, 그에 따라 증가한 계산량이 증가하게 된다. 이를 완화하고자 1x1 convoultion 필터를 적용하여 channel dimension을 줄이도록 설계되었다.

1x1 Convolution은 위의 그림과 같이 activation map의 특정 위치에 해당하는 값들을 채널 축으로 모아 하나의 벡터를 구성하고, 이를 1x1 필터를 채널 축으로 쌓은 벡터를 내적하여 동일한 사이즈의 activation map을 얻는 형태로 동작한다.
이때 필터의 개수에 따라 출력의 channel dimension이 결정되기 때문에 입력에 비해 channel dimension을 줄이고 결과적으로 계산량을 줄일 수 있는 것.
1x1 Convolution의 경우 다른 곳에서도 많이 활용되는 테크닉인 만큼 동작 방식과 기대 효과를 정확하게 이해하고 넘어가는 것을 권장

GoogLeNet의 전체 구조
위의 그림에서 확인할 수 있듯이 Stem network는 vanilla convolution network로 구성
이후 앞서 살펴보았던 Inception module을 중첩해서 쌓는 형태로 구성이 되는데, 네트워크의 중간중간에 auxiliary classifier가 추가적으로 구성
Auxiliary classifier의 경우, 강의 초반에 언급했던 gradient vanishing 문제를 완화하기 위해 추가
레이어의 중간중간에 추가적인 gradient를 주입시키는 방식
물론 이는 학습에만 사용되고, test time에서는 사용하지 않는다.
- ResNet
지금까지도 활발하게 사용이 되고 있을만큼 큰 임팩트를 줬던 ResNet에 대해 알아보겠습니다.
ResNet은 100개 이상의 깊은 층을 갖는 구조를 가지고 ImageNet에서 최초로 인간보다 뛰어난 성능을 달성하며, 더 깊은 층을 쌓을수록 성능이 좋아진다는 것을 보여준 첫 논문
허나 앞서 설명하였듯이 이전에도 연구자들은 네트워크의 층을 깊게 쌓고자 시도하였지만 여러 문제에 부딪히며 실패. 그럼 ResNet은 이러한 문제들을 어떻게 해결할 수 있었을까?
연구자들은 네트워크의 층이 깊어지고, 파라미터 수가 증가할 수록 오버피팅에 취약하여 학습 에러는 비교적 낮아질 것이라고 생각
허나 그래프에서는 56개의 레이어로 구성된 네트워크의 학습 에러가 20개의 레이어로 구성된 네트워크보다 크게 측정되었고, 연구자들의 생각과 반대되는 결과를 보여주었다.
연구자들은 이러한 결과를 통해 층이 깊어질수록 오버피팅 문제가 아닌 degradation 문제로 인해 최적화하기 어려워져서 낮은 성능을 보이는 것이라고 결론

위의 그림을 통해 이 문제에 대한 ResNet의 연구가설을 알아보도록 하겠습니다.
좌측과 같이 일반적인 구조로 H(x)라는 특정 mapping을 학습할 때 층을 깊게 쌓아, x로 부터 곧바로 H(x)를 학습하려고 한다면 복잡하기 때문에 학습하기 어려울 것
반면 우측과 같이 입력에서 주어진 identity x를 제외한 나머지 부분, F(x)만 모델링하여 학습시킨다면 학습의 부담을 경감하여 그 난이도를 낮출 수 있을 것
이러한 가설을 구현하고자 논문에서는 shortcut connection(skip connection, residual connection)을 제안
이때 중요한 점은 shortcut connection에도 gradient가 흐를 수 있도록 설계하여, gradient vanishing 문제를 해결할 수 있었다는 점
또한 Residual block의 수를 n이라고 할 때, gradient는 $2^n$ 개의 다른 경로로 흐를 수 있게 되는데, 이렇게 다양한 경로를 통해서 굉장히 복잡한 매핑을 학습해낼 수 있기 때문에 좋은 성능을 달성할 수 있었다고 한다.

위의 그림과 함께 ResNet의 전체 구조를 살펴보겠습니다.
첫 번째로 ResNet은 7x7 convolution layer로 시작하며, ResNet에 적합한 초기화 방법인 He initialization 방법을 통해 가중치를 초기화한다.
다음으로 residual block을 깊게 쌓아 깊을 층을 가지도록 설계되었다.
각 residual block에서는 3x3 필터를 사용하기 때문에 층을 깊게 쌓더라도 파라미터 수가 급격하게 증가하지 않도록 설계되었다.
생각해보기
• 본 강의에서 설명하였던 shortcut connection(skip connection, residual connection)의 경우, ResNet 이후 제안된 모델에서도 활발하게 활용되었습니다. 어떠한 예시들이 있을지 스스로 학습해봅시다.
Image Classification (3) : 모델 비교
Beyond ResNet
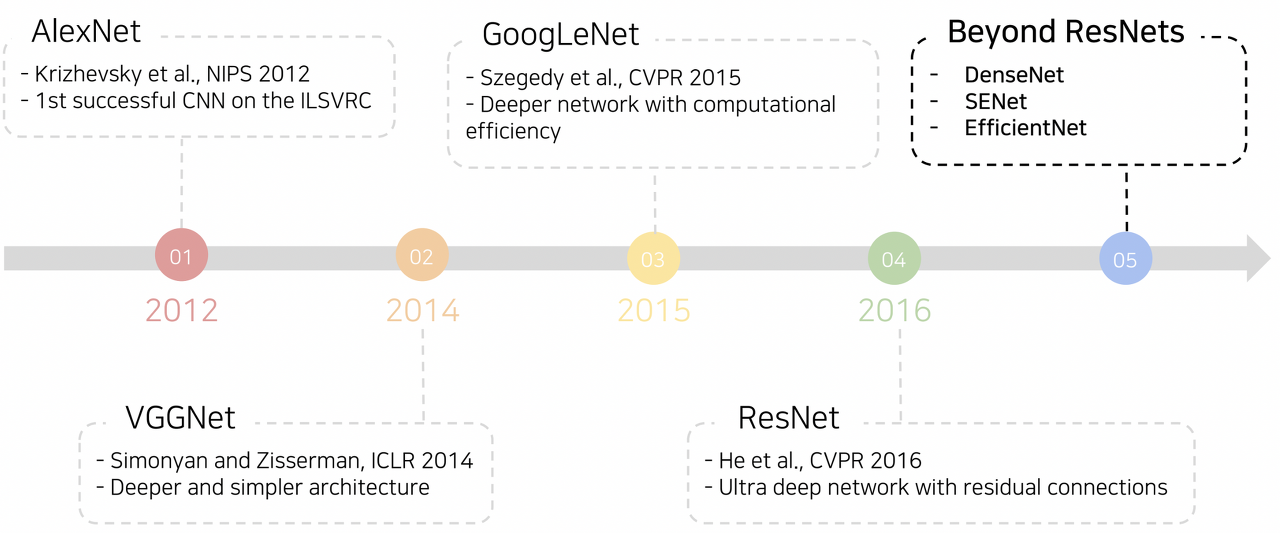
ResNet 이후에 등장한 주요 모델들을 알아보겠습니다.
- DenseNet
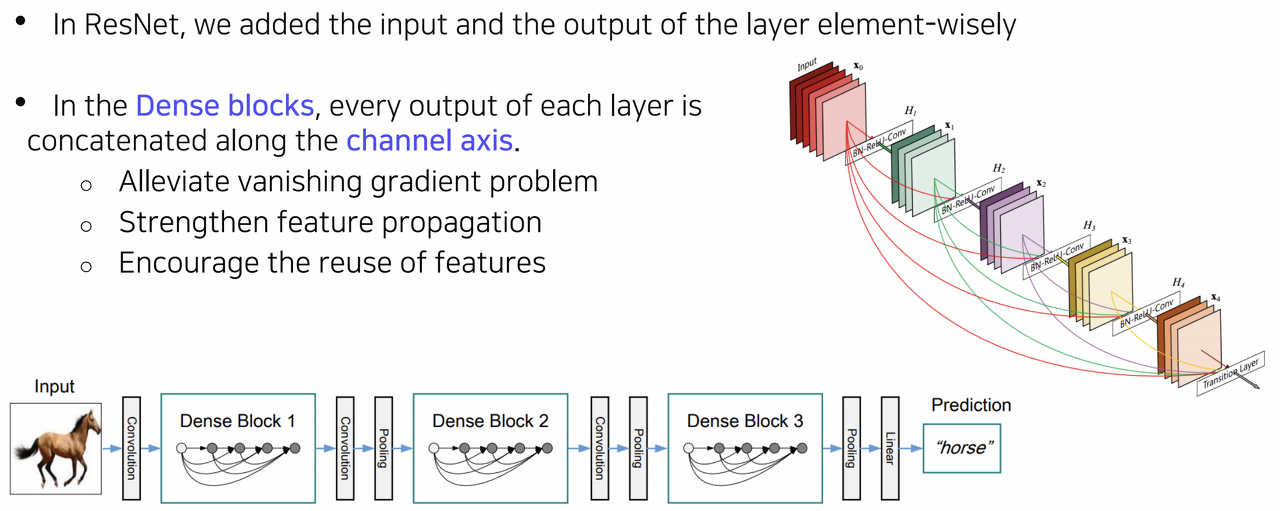
Residual block에서는 skip connection을 통해 identity mapping을 구현했지만, Dense block에서는 채널 축을 중심으로 concatenation을 수행하도록 되어있다.
이때 바로 직전의 입력만 연결하는 것이 아니라 그 이전의 입력들도 모두 연결하도록 dense하게 설계되어 있다.
이렇게 상위 레이어에서도 하위 레이어의 특징을 참고할 수 있도록 하여 보다 복잡한 매핑을 학습하기 용이하도록 설계되어 있다.
이때 skip connection처럼 값을 합하는 것이 아니라 concatenation하기 때문에 파라미터 수가 증가하고 계산이 복잡해진다는 단점을 가진다.
- SENet
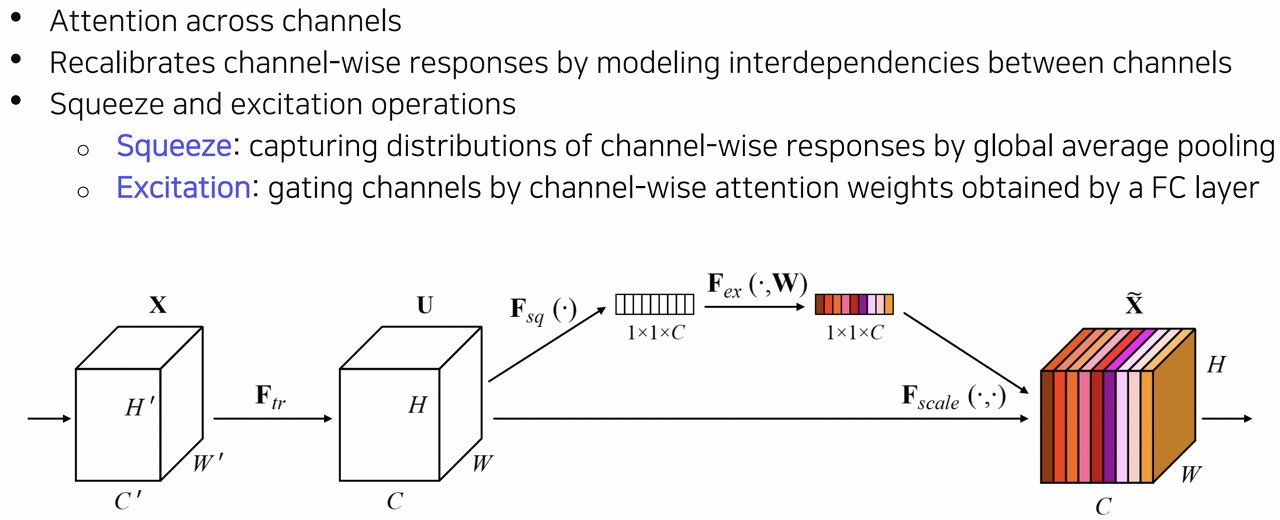
SENet은 depth를 높히거나 connection을 추가해주는 것이 아닌, 채널 축을 중심으로 feature map에 대한 attention을 계산함으로서 각 채널 간의 관계를 모델링하고 중요한 특징에 보다 큰 가중치를 부여할 수 있도록 설계되었다.
이때 attention을 계산하는 과정은 Squeeze와 Excitation 과정으로 나누어진다.
Squeeze 과정에서 global average pulling을 수행하여 채널 축의 분포를 얻고, 이를 FC layer에 통과시켜 채널 축으로 feature map을 gating하기 위한 attention score를 계산한다.
Excitation 과정에서는 Squeeze 과정에서 얻은 channel-wise attention score로 feature map을 gating(rescaling)시켜준다.
즉 중요도가 떨어지는(attention score가 낮은) channel의 feature map 게이트를 닫게되고, 중요도가 높은 경우 그 반대로 만들어줘서 중요한 특징에 집중할 수 있도록 하는 방법이라고 볼 수 있다.
- EfficientNet
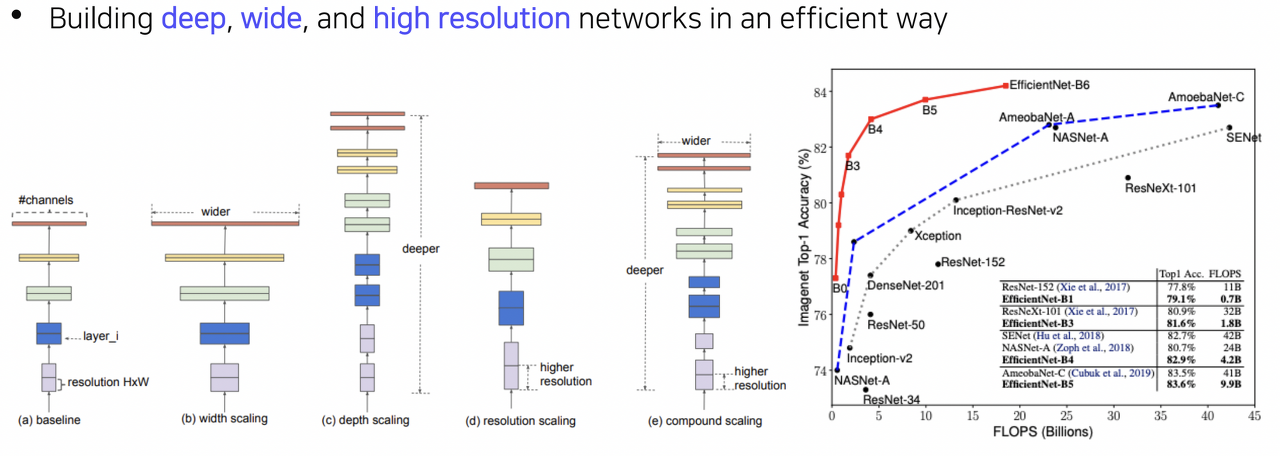
보통 CNN 구조를 기반으로 더 좋은 성능을 달성할 수 있는 구조를 설계하는 방법은 주로 (b) width scaling [Ex. Inception module of GoogLENet], (c) depth scaling [Ex. ResNet], (d) resolution scaling 중의 하나인 경우가 대부분이었다.
이 세 가지 방식은 대체로 성능이 더 좋아지는 경향이 있었으나, 결국에는 saturation되는 경향이 확인되었다.
이러한 부분을 착안하여, 세 가지 방식을 적절하게 활용하여 훨씬 좋은 성능을 달성하는 것을 목표로 제안된 것이 바로 EfficientNet의 (e) compound scaling이다.
그리고 실제로도 위 그림의 그래프를 보면 사람이 직접 고안함으로써 발전해온 CNN 계열의 모델의 성능 증가 폭, NAS(Neural Architecture Search) 기반으로 제안된 모델의 성능 증가 폭, 그리고 EfficientNet의 성능 증가 폭을 비교했을 때 EfficientNet이 동일 FLOPS 당 압도적인 성능 증가 폭을 보여주는 것을 확인할 수 있다.
Deformable Convolution
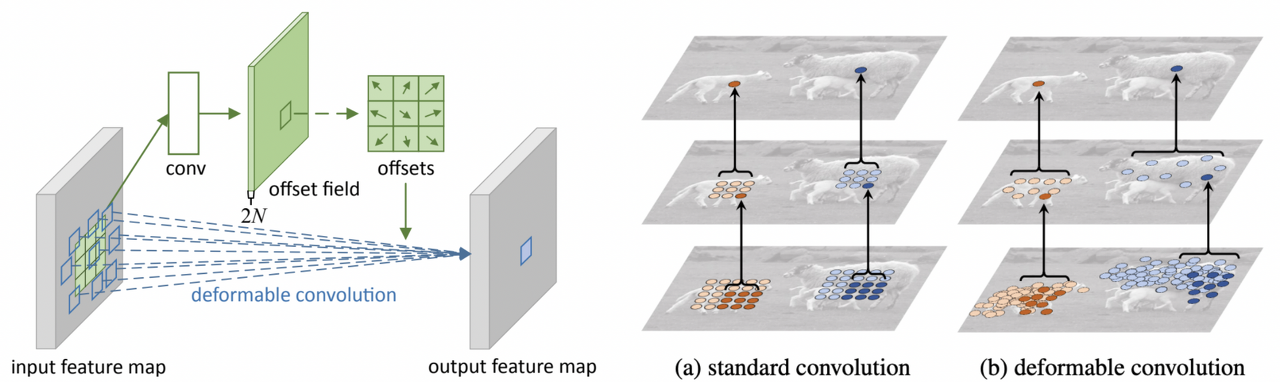
일반적인 convolution이 아닌 불규칙적인 convolution을 수행하는 Deformable Convolution 방법
이는 모든 구성요소의 위치가 정해져있는 자동차, 서랍장 등과 다르게 동물이나 사람 등의 경우 그 움직임에 따라 각 구성요소들의 상대적인 위치가 달라질 수 있다.
이러한 deformable한 부분들을 잘 고려하여 convolution을 수행하고자 제안된 방법이다.
Deformable Convolution은 기본적인 convolution 연산을 수행하는 부분과 별도로 2D offset map을 추정하기 위한 부분이 있다.
이러한 구조를 기반으로 먼저 입력 이미지에 대해 2D offset map을 추정하고, 기본적인 convolution 연산을 수행할 때 input feature map에서 참고하는 가중치들을 2D offset map 값에 따라 벌려주게 된다.
따라서 receptive field가 deformable한 shape을 따라 결정된다고 볼 수 있다.
Summary of Image Classification
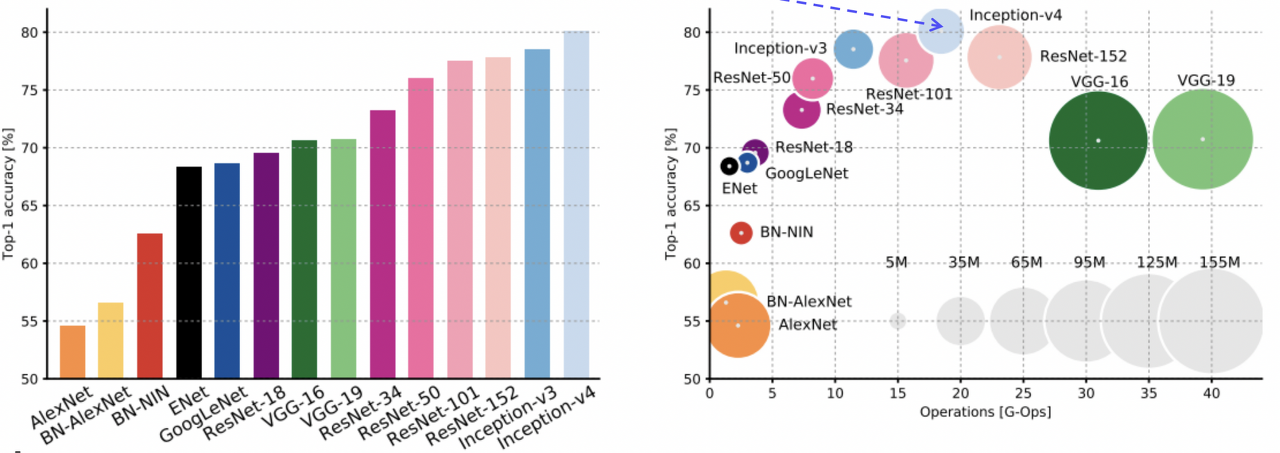
지금까지 다뤘던 CNN 모델들을 종합하여 살펴보겠습니다.
AlexNet은 ImageNet 스케일에서 동작하는 가장 간단한 구조라고 볼 수 있다. 따라서 계산이 간단하지만, 용량이 매우 크고, 성능이 비교적 낮다.
VGGNet의 경우 간단한 3x3 convolution을 기반으로 하고 있지만 비교적 최근에 등장한 모델과 비교해도 모델 사이즈가 가장 크다. 이에 따라 계산량 또한 부담이 크다.
Inception 계열 모델(GoogLeNet)의 경우 inception module과 auxiliary classifier를 사용하여 ResNet보다도 높은 성능을 보이지만, EfficientNet에 비해서는 낮은 성능을 보인다.
ResNet의 경우 depth scaling을 통해 깊은 네트워크 구조를 가지며 뛰어난 성능을 달성했지만, Inception 계열에 비해서는 무겁고, 계산량이 많으며 성능 또한 더 낮았다.
CNN Backbones
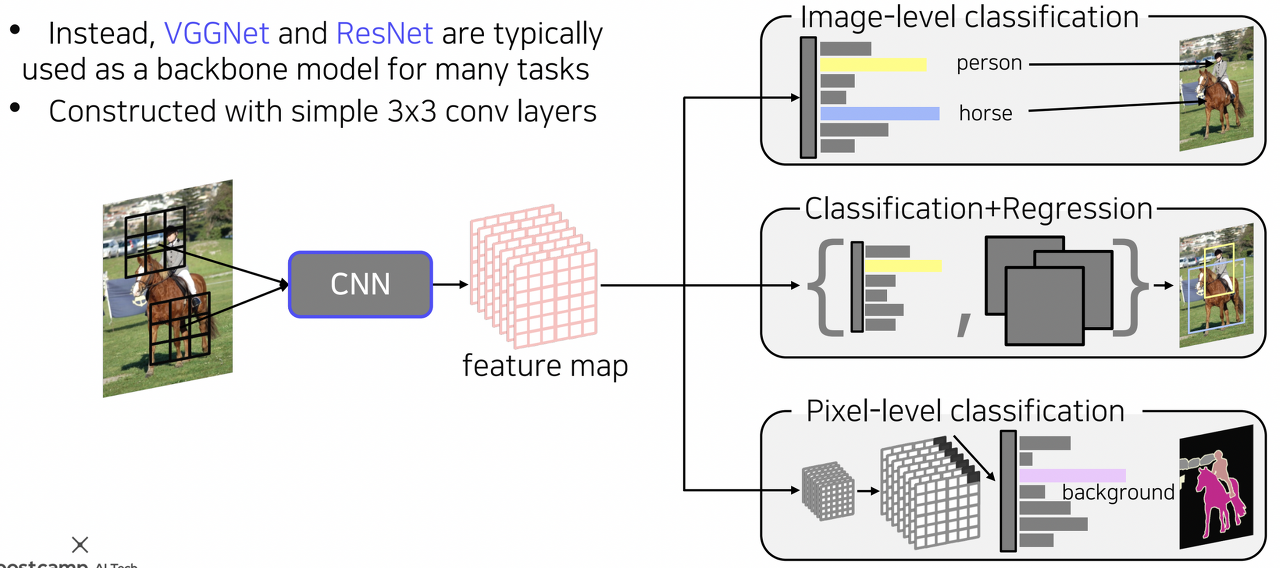
앞서 성능을 비교해본 그림에서 확인할 수 있듯이 Inception 계열의 모델은 AlexNet, VGGNet, ResNet에 비해 효율적이면서도 높은 성능을 보여주는 강력한 네트워크임을 알 수 있다.
허나 auxiliary classifer 등 다양한 task에 적용하기에는 구현이 난해한 부분이 있어 일반적으로는 VGGNet 혹은 ResNet이 많이 사용된다.
생각해보기
• SENet 파트에서 간략하게 다룬 attention의 경우, transformer의 기반이 되는 매우 중요한 매커니즘입니다. Vision 분야에서 attention 그리고 transformer를 활용하여 어떠한 연구가 진행되었는지 스스로 학습해봅시다.
'머신러닝, 딥러닝 > 컴퓨터비전' 카테고리의 다른 글
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (3. Seg & Det - 2) (0) | 2023.02.13 |
|---|---|
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (3. Seg & Det - 1) (0) | 2023.02.05 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (2. 컴퓨터 비전과 딥러닝 - 1) (0) | 2023.02.05 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (1. 컴퓨터 비전의 시작) (0) | 2023.02.04 |
| 컴퓨터비전 용어 정리 (0) | 2023.01.17 |



