네이버 부스트코스의 '컴퓨터 비전의 모든 것' 정리 내용입니다.
Object Detection

Computer Vision 분야에는 가장 간단한 Image Classification부터 Semantic Segmentation, 그리고 더 발전된 task인 Instance Segmentation, Panoptic Segmentation등의 task들이 있다. 이때 각 개체들을 구분하기 위해서는 본 강의에서 소개할 Object Detection 기술이 필요하다. 따라서 Object Detection은 Semantic Segmentation을 보다 근본적인 scene understanding 기술이라고 보면 될 것 같다.
What is Object Detection?
Object Detection은 classification과 bounding box를 동시에 예측하는 문제라고 볼 수 있다. 위의 그림과 같이 특정 물체의 위치를 bounding box의 형태로 예측하고, 해당 물체의 클래스까지 분류해내는 task이다.
What are the Applications of Object Detection?
이렇게 찾은 물체의 위치 정보와 카테고리 정보는 다양한 분야에 활용될 수 있다. 대표적인 예시로 자율주행 기술, OCR(Optical Character Recognition) 등을 생각해볼 수 있다. 그만큼 Object Detection의 산업 가치가 매우 크다고 볼 수 있다.
Two-stage Detector (R-CNN family)
최근의 Object Detection은 two-stage detector와 single-stage detector로 나뉘어 빠르게 발전하고 있다. 먼저 R-CNN 계열의 two-stage detector들을 살펴보도록 하겠다.
R-CNN
본격적으로 첫 번째 딥러닝 기반의 접근으로 Object Detection을 해결해낸 R-CNN에 대해 위의 그림과 함께 살펴보겠다. 기본적인 이미지 classification을 최대한 잘 활용하기 위해 간단한 프로세스를 가진다. 먼저 Selective search 등의 huristic한 방법을 통해 region proposal을 구해낸다. 참고로 R-CNN에서는 약 2천개 이하로 구했다고 한다. 이렇게 얻은 region들을 CNN classification에 활용할 수 있도록 적절한 사이즈로 warping해준다. 이 warped region을 CNN으로 feature를 추출하고, SVM으로 classification하여 결과적으로 region에 대한 classification을 수행한다. 단점으로는 reigion proposal 하나하나 마다 classification을 수행해주어야 하기 때문에 속도가 매우 느리다는 단점이 있고, end-to-end network가 아니기 때문에 학습을 통한 성능 향상이 제한되어 있다는 한계가 있다. (region proposal이 hand design되어 사용되기 때문에)
Fast R-CNN
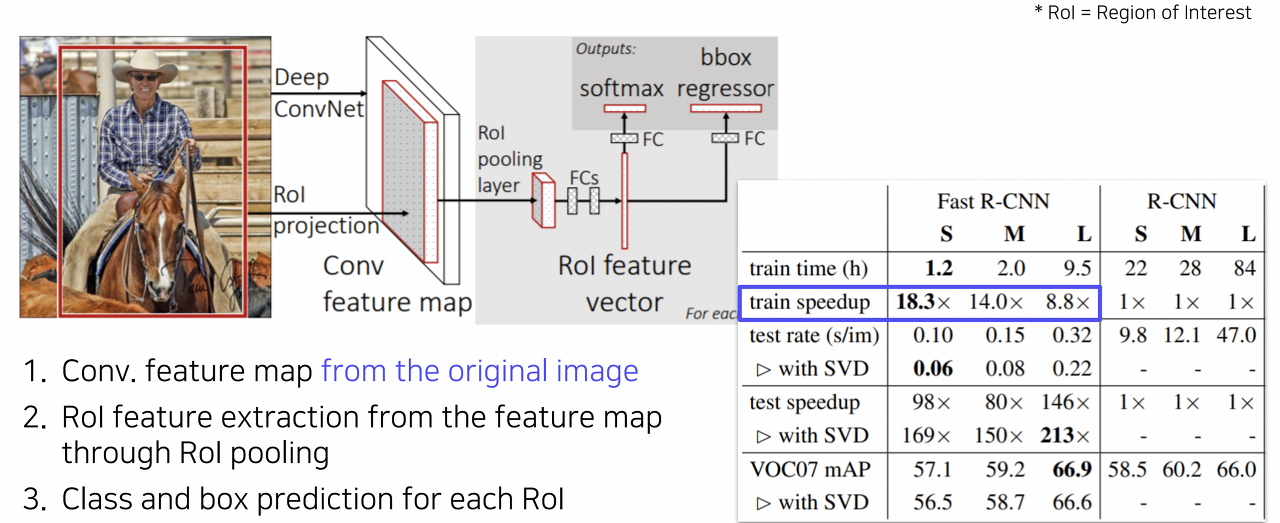
이렇게 R-CNN이 갖는 느린 속도를 개선하고자 동일한 저자들이 Fast R-CNN 구조를 제안하였다. 이 방법에서의 핵심은 이미지 전체에 대한 feature를 한번에 추출하고, 이를 재활용하여 여러 object들을 탐지할 수 있도록 한 것이다. 그 구체적인 과정을 살펴보겠다. 먼저 convolution layer를 통해 입력 이미지 전체의 feature map을 추출한다. 그 이후 이러한 feature map을 여러번 반복하여 재활용하기 위해 ROI(Region Of Interest) Pooling 기법을 사용한다. 즉 전체 feature map에서 ROI에 해당하는 부분만 추출하는 것이다. 이후 이를 고정된 사이즈로 resampling 한다. 이를 기반으로 FC layer를 거쳐 region에 대한 classification을 수행하고, 더 정확한 bounding box를 얻기 위해 bounding box regression을 수행한다. 이러한 방법을 통해 R-CNN에 비해 약 18배 빠른 속도를 달성할 수 있었지만, 여전히 region proposal을 위해 huristic한 방법을 사용하고 있었기 때문에 성능을 크게 향상시킬 순 없었다.
Faster R-CNN
이러한 흐름을 고려할 때 Faster R-CNN에서는 region proposal을 개선했다는 것을 예측할 수 있다.
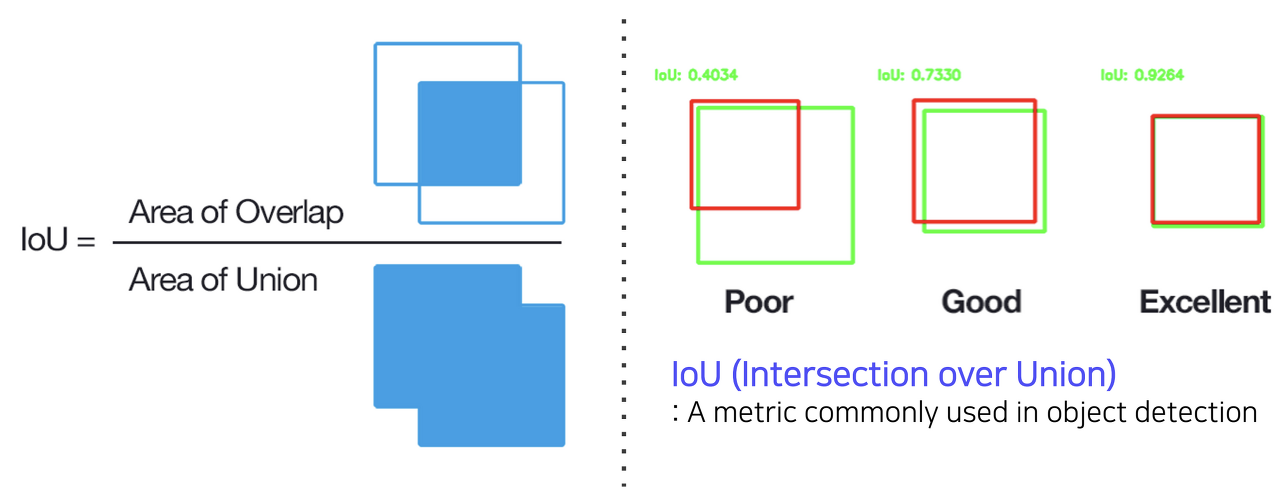
Faster R-CNN에서는 region proposal까지 neural network 기반의 방법을 활용하여 최초의 end-to-end object detection 구조를 제안했다. 본격적으로 Faster R-CNN의 구조를 살펴보기 이전에, IOU(Intersection Over Union)를 간단하게 살펴보도록 하겠다. 두 영역의 overlap을 측정하는 지표로써, 중복되는 영역의 넓이를 두 영역을 합한 영역의 넓이로 나눠준 값이다. 즉 이 값이 높을 수록 두 영역이 잘 정합한다고 볼 수 있다.
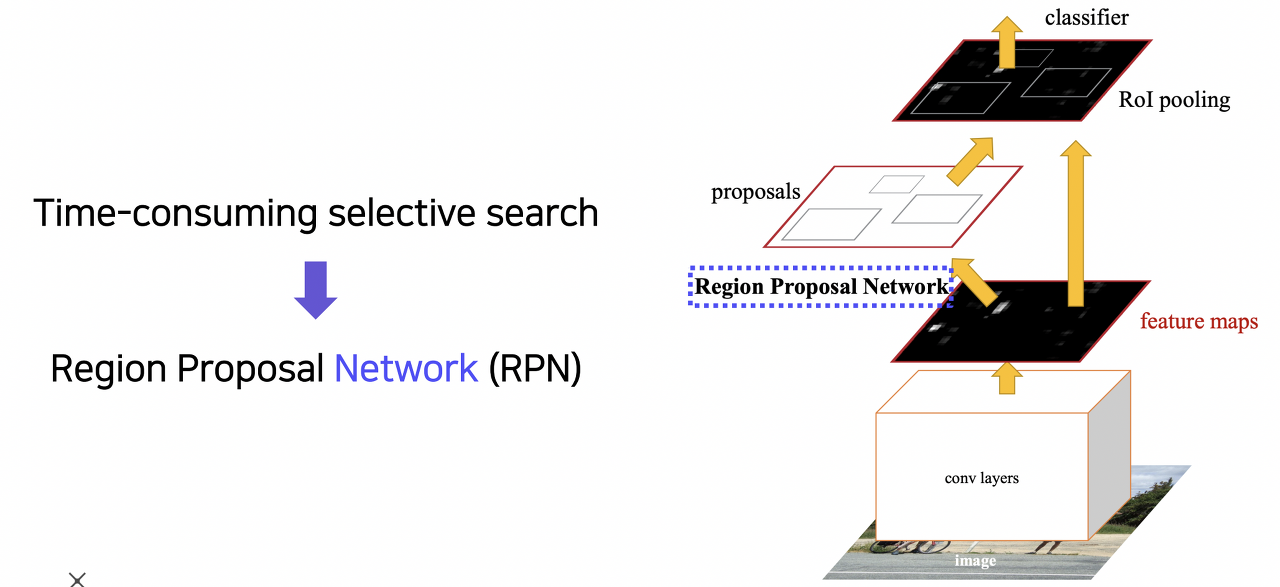
그럼 Faster R-CNN에서 사용한 region proposal 방식을 anchor box라는 개념과 함께 알아보도록 하겠다. Faster R-CNN에서 가장 핵심적인 변화는 기존의 time-consuming selective search 방법이 아닌 Region Proposal Network (RPN) 모듈을 통해 region proposal을 수행한다는 점이다.
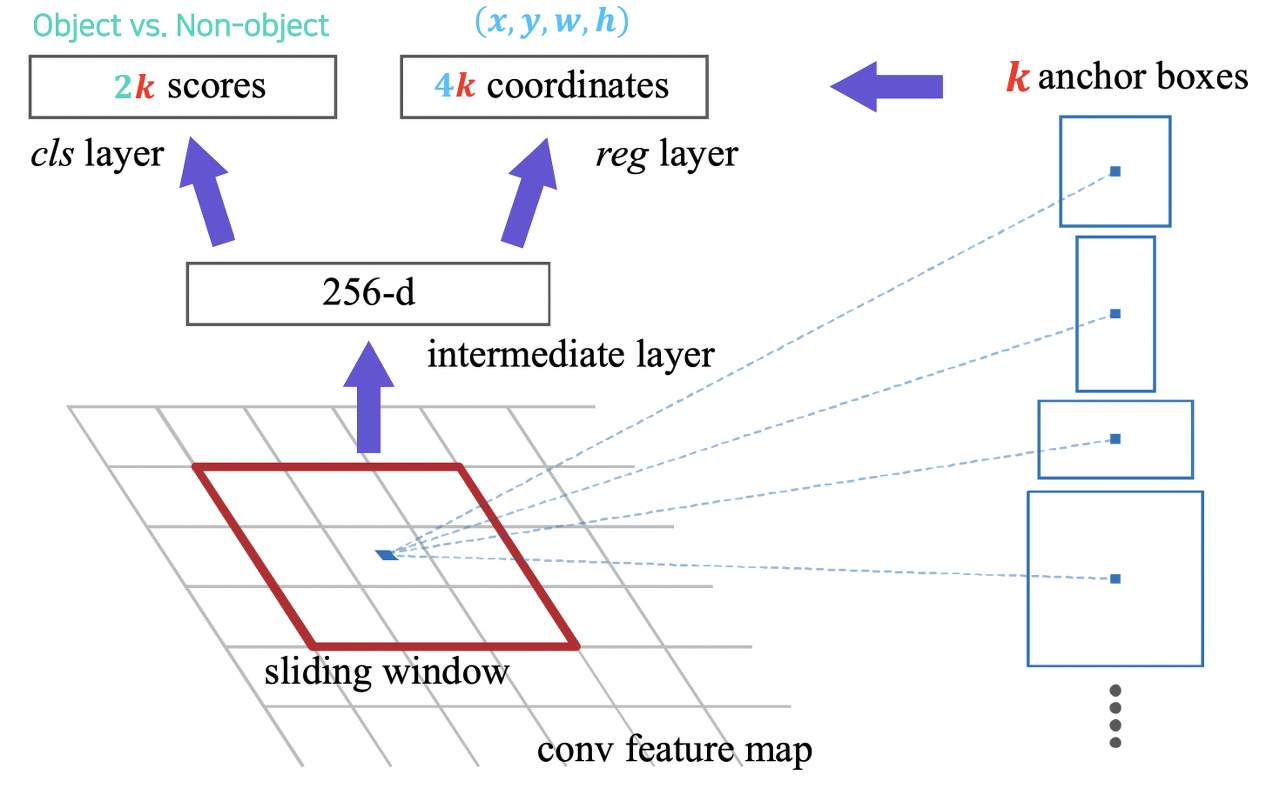
RPN의 구조는 위의 그림과 같다. Sliding window 방식으로 각 픽셀의 위치마다 k개의 anchor box를 고려한다. Anchor box는 각 픽셀 위치에서 발생할 확률이 높은 bounding box들을 사전에 정의해둔 일종의 후보군이라고 볼 수 있으며, Faster R-CNN에서는 서로 다른 크기와 비율을 가진 9개의 anchor box를 사용했다. 구체적으로 anchor box를 고려하는 방식을 알아보겠다. 먼저 각 픽셀 위치에서 256 차원의 feature 벡터를 추출한다. 이 벡터를 입력으로 classfication layer를 거쳐 object인지 object가 아닌지를 판별하는 2k개의 classification 점수를 출력하고, regression layer를 거쳐 4k개의 좌표값을 출력한다. 물론 여기서 사용되는 Loss는 RPN을 위한 것이고, 전체 ROI에 대한 classification loss는 따로 계산된다고 보시면 될 것 같다.
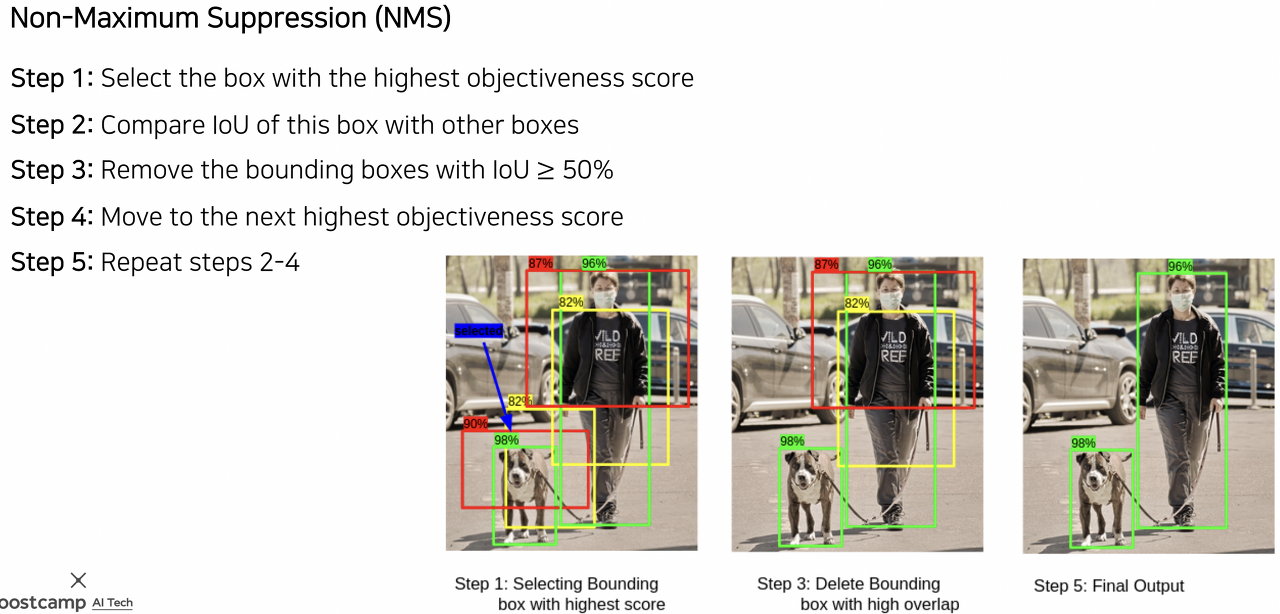
이렇게 RPN을 활용하게 되면 threshold 값을 통과하는 region 중에서 중복되고 겹치는 부분이 많은 region이 많이 발생하게 된다. 이러한 region을 삭제해주기 위해 위와 같이 Non-Maximum Suppersion (NMS)를 사용해준다. 그 과정의 위의 그림과 같고, 딥러닝 이전부터 세대에서부터 대부분의 object detection 알고리즘에 활용되었던 기법이다.
Single-stage Detector
YOLO
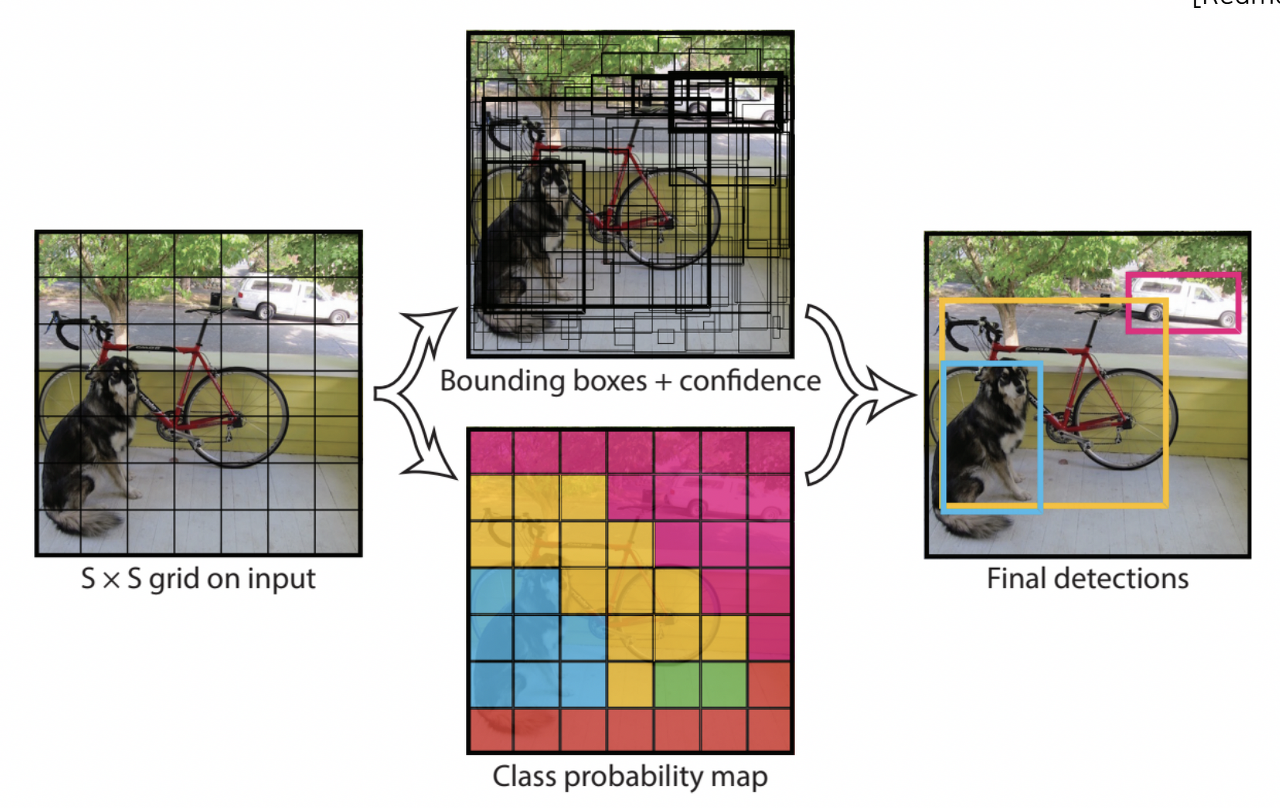
대표적인 single-stage detector로는 YOLO가 있다. 구체적으로 동작방식을 살펴보면, 먼저 입력 이미지는 SxS의 그리드로 나눈다. 각 그리드에 대해서 bounding box의 좌표와 그에 대한 confidence score, 그리고 classification score를 예측한다. 최종 결과는 이전과 마찬가지로 NMS를 통해 정리된 bounding box만을 출력하게 된다.
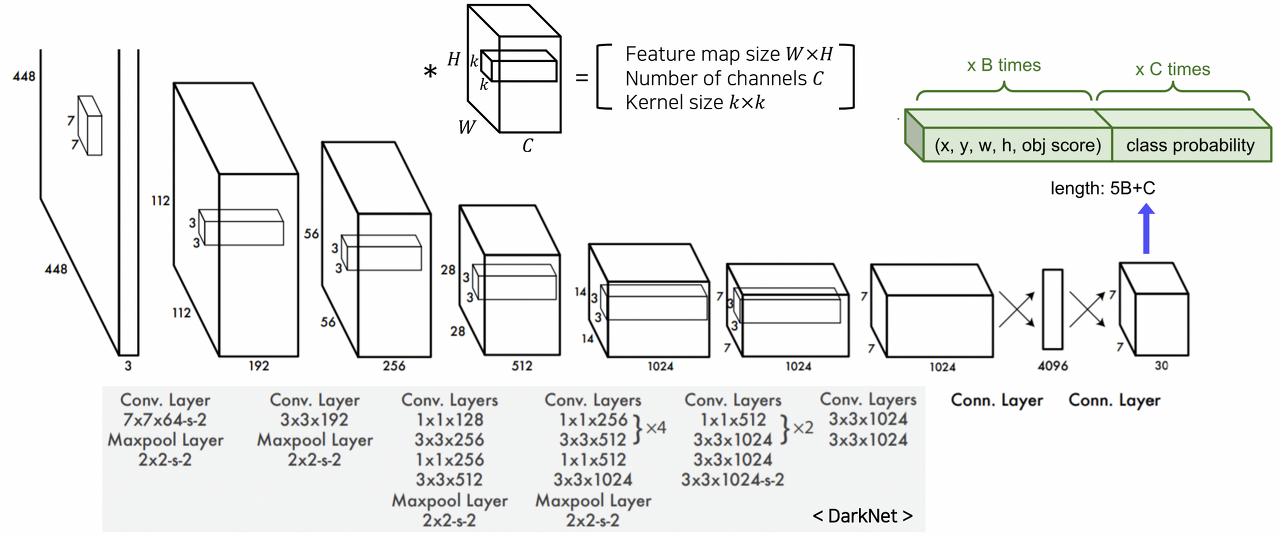
그 구조를 보다 자세하게 살펴보면 위와 같이 일반 CNN의 구성과 유사하다. 이때 최종 출력이 7x7x30인 것을 확인할 수 있는데, 이는 YOLO에서 최종적으로 예측하는 것이 5(4개의 좌표값 + confidence score)*B(anchor box의 개수, 2) + C(class의 개수, 20)이라 각 위치마다 30 차원의 벡터를 출력하는 것이다.
SSD (Single Shot MultiBox Detector)
...
'머신러닝, 딥러닝 > 컴퓨터비전' 카테고리의 다른 글
| [컴퓨터비전] Super Resolution (0) | 2023.05.01 |
|---|---|
| COCO, Pascal VOC data format (Object detection) (0) | 2023.04.21 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (3. Seg & Det - 1) (0) | 2023.02.05 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (2. 컴퓨터 비전과 딥러닝 - 2) (0) | 2023.02.05 |
| [컴퓨터비전] 컴퓨터 비전의 모든 것 (2. 컴퓨터 비전과 딥러닝 - 1) (0) | 2023.02.05 |



